
Introdução
Você abre um chatbot e digita: “Explique a Teoria da Relatividade.”
Segundos depois, uma resposta completa, organizada e didática aparece na tela. Parece mágica. Parece instantâneo. Parece simples.
Mas o que aconteceu nesses poucos segundos?
Quantos computadores trabalharam para produzir aquele texto? Quanta energia elétrica foi consumida? Quantos cálculos matemáticos foram executados? Quanta água foi usada para resfriar as máquinas? Quanto custa, de fato, transformar uma pergunta em uma resposta?
A maioria das pessoas nunca para para pensar nisso. E é compreensível: a interface foi projetada exatamente para esconder a complexidade. Você vê uma caixa de texto e uma resposta. O que existe entre os dois é invisível.
Mas o que existe entre os dois é colossal.
Por trás de cada resposta de uma IA existe uma das maiores e mais caras infraestruturas computacionais já construídas pela humanidade: milhares de processadores especializados, data centers do tamanho de quarteirões, redes de comunicação global, sistemas de refrigeração industrial e trilhões de operações matemáticas executadas em frações de segundo.
Este artigo é sobre essa infraestrutura invisível. Sobre o que realmente acontece quando você faz uma pergunta. Sobre o custo real de pensar — em energia, em silício, em matemática e em dinheiro.
Vamos descobrir, com números públicos e verificáveis, quanto trabalho existe por trás de uma resposta que parece simples.

A ilusão da simplicidade
Pegue a pergunta mais banal possível: “Qual a capital da França?”
Do ponto de vista do usuário, o que acontece é:
Pergunta → Resposta
Dois passos. Imediato. Trivial.
Mas a realidade é muito diferente. Quando você pressiona Enter, a sequência real de eventos é aproximadamente esta:
Pergunta → Internet → Data Center → GPUs → Modelo → Inferência → Probabilidades → Resposta
Sua pergunta sai do seu dispositivo, viaja por cabos de fibra óptica, passa por roteadores e servidores intermediários, chega a um data center que pode estar a milhares de quilômetros de distância, é distribuída para processadores especializados, processada por um modelo com bilhões de parâmetros, convertida em uma distribuição de probabilidades sobre milhares de palavras possíveis e, finalmente, devolvida a você como texto.
Tudo isso em menos tempo do que leva para piscar algumas vezes.
A palavra-chave aqui é uma frase que vale a pena gravar:
Pensar é computar.
Quando dizemos que uma IA “pensa”, o que realmente acontece é computação — operações matemáticas executadas em hardware físico, consumindo energia física, gerando calor físico. Não há mágica. Há engenharia em uma escala que a maioria das pessoas nunca imaginou.
E é justamente porque essa engenharia é invisível que ela é tão fascinante. Vamos abrir a caixa preta.
O que acontece no primeiro milissegundo
Antes mesmo de o modelo “pensar”, sua pergunta já passou por várias transformações.
Quando seu texto chega ao sistema, ele não pode ser processado como palavras — computadores não entendem palavras, entendem números. O primeiro passo é a tokenização.
Um token é um pedaço de texto: pode ser uma palavra inteira, parte de uma palavra ou até um sinal de pontuação. A frase “Qual a capital da França?” pode ser dividida em algo como sete ou oito tokens, dependendo do modelo. A regra prática mais usada na indústria é que, em inglês, um token equivale a aproximadamente três quartos de uma palavra; em português, a proporção costuma ser um pouco menos eficiente.
Depois da tokenização, cada token é convertido em um número (um identificador no vocabulário do modelo) e, em seguida, transformado em um embedding — um vetor de centenas ou milhares de números que representa o “significado” daquele token em um espaço matemático multidimensional.
É só nesse ponto que o texto se torna algo com que o modelo pode trabalhar: uma sequência de vetores numéricos. A palavra “rei”, por exemplo, vira uma lista de números que, no espaço de embeddings, fica matematicamente próxima de “rainha”, “trono” e “monarca” e distante de “banana” ou “asfalto”.
Em resumo, antes de qualquer “raciocínio”:
Texto → Tokens → Números → Embeddings
Toda essa preparação acontece em uma fração de segundo, mas já envolve consultas a tabelas de vocabulário e operações vetoriais. O modelo ainda nem começou a gerar a resposta — e o trabalho computacional já está em andamento.
O cérebro da IA não é uma CPU
Aqui está um ponto que surpreende muita gente: a IA moderna quase não roda em CPUs — os processadores que estão no seu notebook ou celular.
Para entender por quê, é preciso comparar dois tipos de processador:
A CPU (Central Processing Unit) é um processador de propósito geral. Ela tem poucos núcleos muito poderosos, otimizados para executar tarefas complexas em sequência, uma de cada vez, com muita velocidade. É excelente para a maioria das tarefas do dia a dia.
A GPU (Graphics Processing Unit) foi originalmente criada para renderizar gráficos de videogames, mas tem uma arquitetura radicalmente diferente: ela tem milhares de núcleos menores, projetados para executar muitas operações simples simultaneamente. É a definição de processamento paralelo massivo.
Por que isso importa para a IA? Porque o “pensamento” de um modelo de linguagem é, em essência, uma sequência gigantesca de multiplicações de matrizes — e a multiplicação de matrizes é o exemplo perfeito de uma operação que pode ser dividida em milhares de cálculos independentes executados ao mesmo tempo. É exatamente para isso que as GPUs foram feitas.
Existe ainda um terceiro tipo, a TPU (Tensor Processing Unit), desenvolvida pelo Google especificamente para acelerar operações de aprendizado de máquina. As TPUs são chips projetados desde o início para um único propósito: fazer a matemática das redes neurais o mais rápido e eficiente possível.
A escala desses processadores é notável. A NVIDIA H100, uma das GPUs mais usadas para IA até recentemente, possui cerca de 80 bilhões de transistores e atinge quase 2.000 trilhões de operações por segundo em determinadas precisões matemáticas. Sua sucessora, a arquitetura Blackwell (B200), reúne dois chips em um único módulo para superar os limites físicos de fabricação de um chip único.
A lição central: a IA depende de um tipo de processamento que a computação tradicional simplesmente não foi feita para fazer de forma eficiente. Sem o processamento paralelo massivo das GPUs e TPUs, os modelos que usamos hoje seriam economicamente inviáveis.
O verdadeiro trabalho: inferência
Aqui chegamos ao coração do artigo. E começamos desfazendo uma confusão comum.
Existem duas fases completamente diferentes na vida de um modelo de IA: treinamento e inferência.
Treinamento é o processo de ensinar o modelo. É quando ele processa enormes volumes de texto, ajusta bilhões de parâmetros internos e “aprende” padrões da linguagem. Acontece uma única vez (ou poucas vezes), antes do modelo ser lançado, e custa uma fortuna.
Inferência é o processo de usar o modelo. É o que acontece toda vez que você faz uma pergunta. O modelo já aprendeu; agora ele aplica esse conhecimento para gerar uma resposta.
A analogia mais clara: treinamento é estudar para uma prova durante meses; inferência é responder a uma questão da prova. O estudo é longo e caro e acontece uma vez. Responder a uma questão é rápido — mas se milhões de pessoas fazem perguntas o tempo todo, a soma de todas essas “respostas rápidas” se torna gigantesca.
E é exatamente isso que aconteceu. Com a popularização dos chatbots, a inferência passou a consumir mais recursos do que o treinamento. Um único treinamento, por mais caro que seja, é finito. Mas quando uma ferramenta tem centenas de milhões de usuários fazendo perguntas todos os dias, o custo acumulado da inferência ultrapassa o do treinamento.
Toda resposta que você recebe é um processo de inferência. E cada inferência tem um custo concreto em energia, processamento e tempo. Vamos quantificar.
Quantas operações matemáticas existem em uma resposta?
Vamos a uma pergunta que quase ninguém faz: quando você pede “Crie um plano de negócios”, quantos cálculos realmente acontecem?
Para responder, precisamos de um conceito da literatura técnica. Desde o trabalho de Kaplan e colaboradores (2020), nos Scaling Laws for Neural Language Models, a regra prática aceita na indústria é:
Na inferência, cada token gerado custa aproximadamente 2 × N operações de ponto flutuante (FLOPs), onde N é o número de parâmetros do modelo.
O fator 2 vem do fato de que cada parâmetro participa de uma multiplicação e uma soma (uma operação de “multiplicação-acumulação”). É uma aproximação que ignora alguns custos menores, como o mecanismo de atenção, mas captura o essencial.
Vamos colocar números reais nisso.
Considere um modelo da escala do GPT-3, com 175 bilhões de parâmetros. Para gerar um único token, o custo aproximado é:
2 × 175.000.000.000 = 350 bilhões de operações por token
Agora imagine que sua resposta tem 500 tokens (cerca de 350 a 400 palavras) e que sua pergunta tinha 100 tokens. O modelo precisa processar todos esses tokens. A conta fica:
600 tokens × 350 bilhões de operações = 210 trilhões de operações matemáticas
Para uma resposta de tamanho médio. De um único usuário. Em uma única interação.
Esse número — 210 trilhões, ou 2,1 × 10¹⁴ — é difícil de imaginar. Se você fosse fazer uma operação matemática por segundo, sem parar, levaria mais de 6 milhões de anos para completar os cálculos de uma única resposta de IA. As GPUs fazem isso em segundos.
E note que usamos um modelo de “apenas” 175 bilhões de parâmetros, uma escala já antiga. Modelos de fronteira atuais podem ter arquiteturas maiores e mais complexas (embora muitos usem técnicas como mixture-of-experts, que ativam apenas parte dos parâmetros por token, reduzindo o custo efetivo).
A conclusão é inescapável: cada resposta aparentemente trivial esconde um volume de cálculos que seria impensável fazer manualmente. Pensar, para uma máquina, é fazer trilhões de contas — e fazê-las quase instantaneamente.
O custo invisível dos tokens
Se cada token custa operações matemáticas, então o número de tokens é um dos principais determinantes do custo de uma resposta. E aqui há uma sutileza importante: um token não é apenas uma palavra na tela. Cada token gera processamento, ocupa memória, exige comunicação entre componentes e consome armazenamento temporário.
Isso significa que o custo de uma interação cresce com o número de tokens envolvidos. Não de forma totalmente linear — por causa do mecanismo de atenção, que veremos na próxima seção, respostas muito longas podem ter custos que crescem ainda mais rápido — mas a tendência geral é clara: mais tokens, mais trabalho.
Dados públicos confirmam isso de forma concreta. Análises da Epoch AI estimaram que uma consulta típica ao GPT-4o consome cerca de 0,3 watt-hora de eletricidade. Mas quando se anexa um documento mais longo — como um artigo acadêmico — o consumo sobe para algo em torno de 2,5 watt-horas. E uma consulta que processe um texto muito longo, de 100 mil tokens (o equivalente a cerca de 200 páginas), pode chegar a quase 40 watt-horas.
Ou seja: a mesma ferramenta, o mesmo modelo, pode ter um custo energético mais de cem vezes maior dependendo apenas de quantos tokens estão envolvidos.
Em ordem de grandeza:
- Uma pergunta curta com resposta curta: fração de watt-hora.
- Uma pergunta com um documento anexado: alguns watts-hora.
- Uma análise de um texto muito longo: dezenas de watts-hora.
É por isso que serviços de IA cobram por token (tanto de entrada quanto de saída) e por que engenheiros se preocupam tanto em otimizar o tamanho dos prompts. Cada token tem um preço — em dinheiro, em energia e em tempo. O token é a unidade fundamental de custo da economia da IA.

A memória que precisa acompanhar a conversa
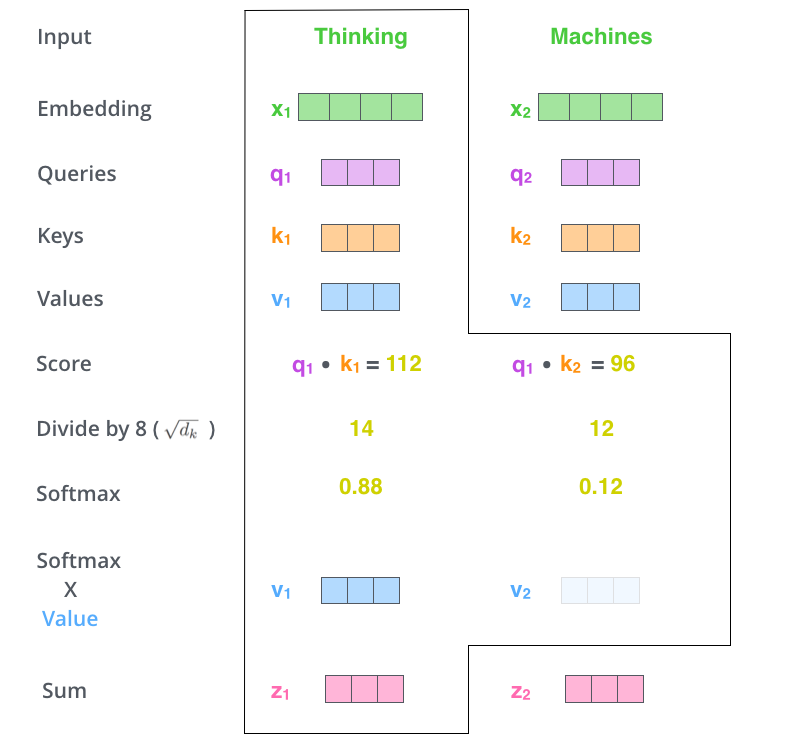
Há um custo adicional que poucos percebem: o sistema precisa “lembrar” de tudo o que já foi dito na conversa.
Esse espaço de memória é chamado de janela de contexto (context window). Tudo o que está na conversa atual — sua pergunta, as mensagens anteriores, os documentos anexados, as respostas já dadas — precisa estar disponível para o modelo a cada novo token gerado.
E aqui está o problema técnico: o mecanismo de atenção, que permite ao modelo relacionar cada token com todos os outros, tem um custo que cresce de forma desproporcional com o tamanho do contexto. Para cada novo token gerado, o modelo precisa “olhar” para todos os tokens anteriores. Quanto maior o contexto, mais pesado fica esse processo.
A diferença é gigantesca. Compare:
- Uma conversa de 100 palavras: o modelo precisa considerar um contexto pequeno, e o custo por token é modesto.
- Uma conversa ou documento de 100.000 palavras: o modelo precisa manter e consultar um contexto enorme a cada passo, e tanto o consumo de memória quanto o de processamento disparam.
Esse é também o motivo pelo qual existe uma estrutura técnica chamada KV cache (cache de chaves e valores): para evitar recalcular tudo a cada token, o sistema armazena temporariamente representações dos tokens já processados. Mas esse cache ocupa memória — e, para contextos muito longos, pode consumir mais memória do que os próprios parâmetros do modelo.
A lição: quando você cola um documento de 50 páginas em um chatbot e pede um resumo, está pedindo muito mais trabalho computacional do que quando faz uma pergunta curta. O contexto não é gratuito. Cada palavra que o sistema precisa “ter em mente” tem um custo real em memória e processamento.
O problema da latência
Por que algumas respostas saem na hora e outras demoram? A resposta tem a ver com um conceito chamado latência.
Latência é o tempo entre você enviar a pergunta e começar a receber a resposta. Vários fatores influenciam:
Distância física. Mesmo viajando à velocidade da luz pela fibra óptica, os dados levam tempo para percorrer milhares de quilômetros até o data center e voltar. Quanto mais perto fisicamente você estiver do servidor, menor a latência.
Congestionamento da rede. A internet é compartilhada. Em horários de pico, há mais tráfego competindo pelos mesmos cabos e roteadores.
Disponibilidade de GPUs. Os processadores que rodam o modelo são um recurso finito e caro. Se todos estão ocupados atendendo outras pessoas, sua requisição entra em uma fila.
Tamanho da resposta. Como o modelo gera um token de cada vez, uma resposta longa simplesmente leva mais tempo para ser produzida do que uma curta.
Há ainda dois conceitos técnicos importantes aqui. A latência mede o tempo de resposta individual. Já o throughput (vazão) mede quantas requisições o sistema consegue processar por unidade de tempo. Operadores de IA estão sempre equilibrando os dois: respostas individuais rápidas versus capacidade de atender muita gente ao mesmo tempo. Frequentemente, agrupar várias requisições juntas (batching) aumenta o throughput, mas pode aumentar a latência de cada resposta individual.
Aquele “tempo de digitação” que você vê quando o chatbot vai revelando a resposta palavra por palavra não é um efeito decorativo: é o reflexo real de que cada token está sendo gerado naquele instante, um após o outro, consumindo processamento a cada passo.
O que acontece dentro de um data center de IA?
Um data center de IA é uma das construções mais impressionantes da engenharia moderna — e a maioria das pessoas nunca viu uma por dentro.
A estrutura básica funciona em camadas. Na base estão os servidores, máquinas que contêm os processadores. Vários servidores são empilhados em racks (armários verticais). Dentro dos servidores ficam as GPUs, conectadas entre si por redes internas de altíssima velocidade.
A escala é o que choca. Um sistema como o NVIDIA GB200 NVL72 reúne 72 GPUs Blackwell e 36 processadores Grace em um único rack refrigerado a líquido — e esse rack sozinho pode consumir cerca de 120 mil watts (120 kW) de energia. Para efeito de comparação, uma casa típica consome alguns milhares de watts no total. Um único rack de IA pode consumir o equivalente a dezenas de residências.
E um data center moderno tem centenas ou milhares desses racks.
Três sistemas precisam funcionar em harmonia:
Computação. As GPUs e TPUs que fazem a matemática. É o “cérebro”.
Rede. Conexões internas de altíssima velocidade que permitem que os processadores troquem dados entre si — porque um modelo grande não cabe em uma única GPU e precisa ser distribuído entre várias, que precisam se comunicar constantemente.
Refrigeração. Todo esse processamento gera calor — muito calor. Sistemas de resfriamento, cada vez mais baseados em refrigeração líquida direta, mantêm os chips em temperaturas operacionais. Sem refrigeração eficiente, o hardware derreteria em minutos.
Quando o treinamento do modelo Llama 3, da Meta (da mesma geração do GPT-4), foi realizado, estima-se que tenha usado cerca de 16 mil GPUs H100 em um data center com capacidade na casa dos 27 milhões de watts (27 MW). Não é uma sala de servidores. É uma instalação industrial dedicada a uma única tarefa: computar.
O custo da energia
Toda essa computação precisa ser alimentada. E aqui os números públicos finalmente nos dão uma noção concreta do custo de “pensar”.
Por muito tempo, circulou a afirmação de que cada consulta a um chatbot consumia cerca de 3 watts-hora de eletricidade — dez vezes mais do que uma busca no Google. Esse número virou manchete em todo lugar. O problema é que ele se mostrou um exagero.
Em 2025, duas fontes primárias trouxeram dados muito mais precisos:
- O Google publicou um estudo afirmando que uma consulta de texto mediana ao Gemini consome cerca de 0,24 watt-hora — comparável à energia de operar um forno de micro-ondas por um segundo.
- Sam Altman, CEO da OpenAI, divulgou em junho de 2025 que uma consulta média ao ChatGPT usa cerca de 0,34 watt-hora e aproximadamente 0,3 mililitro de água.
Análises independentes da Epoch AI chegaram a estimativas semelhantes: cerca de 0,3 watt-hora para uma consulta típica ao GPT-4o, ou seja, dez vezes menos do que a estimativa antiga.
Para contextualizar: 0,3 watt-hora é menos do que uma lâmpada de LED ou um laptop consomem em alguns minutos. Para um usuário individual, mesmo o uso moderado de IA representa uma fração ínfima do consumo energético diário.
Mas há duas ressalvas importantes que evitam o erro oposto — o de minimizar o problema:
Primeiro, consultas longas custam muito mais. Como vimos, processar 100 mil tokens pode consumir quase 40 watts-hora — mais de cem vezes uma consulta simples.
Segundo, a escala muda tudo. Uma consulta individual é barata, mas multiplicada por centenas de milhões de usuários e bilhões de consultas por dia, o consumo agregado se torna significativo em nível de rede elétrica nacional. O custo individual é trivial; o custo coletivo, não.
Um dado animador: o Google relatou que o consumo de energia por consulta caiu cerca de 33 vezes em apenas doze meses, graças a modelos e hardware mais eficientes. A eficiência está melhorando rápido — mas o número total de consultas também está crescendo rápido.
O desafio da escalabilidade
Até aqui, falamos de uma pergunta de cada vez. Mas o que acontece quando milhões de pessoas perguntam ao mesmo tempo?
Esse é o ponto em que a IA deixa de ser apenas um problema de software e se torna, fundamentalmente, um problema de infraestrutura.
Um único modelo de fronteira é grande demais para caber em uma única GPU. Ele precisa ser dividido entre várias GPUs que trabalham em conjunto (uma técnica chamada paralelismo de modelo). E para atender milhões de usuários, não basta um conjunto de GPUs — são necessários milhares deles, organizados em clusters distribuídos.
Vários mecanismos tornam isso possível:
Escalabilidade horizontal: em vez de tornar uma máquina mais potente (o que tem limites físicos), adiciona-se mais máquinas trabalhando em paralelo.
Balanceamento de carga: um sistema distribui as requisições recebidas entre os servidores disponíveis, evitando que alguns fiquem sobrecarregados enquanto outros ficam ociosos.
Inferência distribuída: a tarefa de gerar uma resposta é repartida entre múltiplos processadores que se coordenam.
Filas e batching: quando a demanda supera a capacidade imediata, requisições são enfileiradas e frequentemente agrupadas para processamento mais eficiente.
É por isso que empresas de IA anunciam investimentos bilionários em data centers. As reportagens públicas falam em projetos de infraestrutura na casa das dezenas de bilhões de dólares, com clusters planejados para consumir vários gigawatts de energia — a escala de usinas de geração elétrica.
A inteligência artificial moderna, vista de perto, é tanto uma conquista de software quanto uma conquista de infraestrutura física. O modelo é o algoritmo; mas sem os data centers, as redes, a energia e a refrigeração que o sustentam, ele seria apenas um arquivo inerte. A inteligência, hoje, é um problema de engenharia em escala industrial.
Quanto custa responder uma única pergunta?
Chegamos ao clímax. Vamos juntar tudo e construir uma estimativa — usando apenas dados públicos — de quanto realmente custa uma resposta de IA. Em três cenários.
Cenário 1 — Uma pergunta simples (“Qual a capital da França?”)
Energia: aproximadamente 0,24 a 0,34 watt-hora, com base nos dados de Google e OpenAI. Água: cerca de 0,3 mililitro. Operações matemáticas: na casa das dezenas de trilhões, considerando o tamanho do modelo e uma resposta curta. Custo monetário direto: uma fração de centavo.
Cenário 2 — Um texto médio (“Crie um plano de negócios para uma cafeteria”)
Energia: alguns watts-hora, já que a resposta é mais longa e exige centenas de tokens gerados. Como referência, a avaliação de ciclo de vida do modelo Mistral Large 2, feita em parceria com a agência ambiental francesa ADEME, estimou para uma resposta de 400 tokens um impacto de 1,14 grama de CO₂ equivalente e 45 mililitros de água. Operações matemáticas: centenas de trilhões.
Cenário 3 — Um relatório grande (analisar um documento de 200 páginas)
Energia: até cerca de 40 watts-hora, conforme as estimativas da Epoch AI para o processamento de 100 mil tokens. Isso é mais de cem vezes o custo de uma pergunta simples. Operações matemáticas: quatrilhões.
A comparação é reveladora. A mesma ferramenta pode ter um custo que varia em mais de duas ordens de grandeza dependendo do que você pede. Uma pergunta simples é quase gratuita em termos de recursos. Uma análise extensa é genuinamente cara.
Vale uma nota de honestidade intelectual: esses números são estimativas baseadas em fontes públicas, e as empresas raramente divulgam metodologias completas. Os próprios pesquisadores que produziram esses dados alertam para a falta de transparência do setor. Por isso, trabalhamos com ordens de grandeza, não com precisão absoluta. Mas mesmo as ordens de grandeza já contam uma história clara: pensar custa — e o quanto custa depende fundamentalmente de quanto você pede para a máquina pensar.
Para dar perspectiva sobre a outra ponta, a do treinamento: estima-se que treinar o GPT-4 tenha custado dezenas de milhões de dólares e que o treinamento, nos meses de pico, tenha consumido milhões de litros de água apenas para refrigeração. O treinamento acontece uma vez; a inferência, bilhões de vezes. Juntas, as duas pontas explicam por que a IA se tornou uma das maiores consumidoras de infraestrutura computacional do planeta.
Estamos transformando eletricidade em inteligência?
Recue um passo e observe o quadro completo.
Quando você lê uma resposta de IA, vê palavras. Vê ideias, frases, raciocínios. Vê algo que se parece com pensamento.
Mas o sistema, em seu nível mais fundamental, não vê nada disso. O sistema vê:
- Energia — elétrons fluindo por circuitos de silício.
- Matemática — multiplicações de matrizes, distribuições de probabilidade.
- Silício — bilhões de transistores ligando e desligando.
- Probabilidades — a escolha do próximo token mais provável, repetida milhares de vezes.
Há aqui uma ideia quase filosófica que vale a pena contemplar. Em sua essência mais crua, um sistema de IA é uma máquina que transforma eletricidade em inferência. Você fornece energia elétrica; ele devolve previsões estruturadas que, organizadas, lemos como conhecimento.
Não é diferente, em princípio, de outras grandes transformações da história industrial. A máquina a vapor transformava calor em movimento. O motor elétrico transformava eletricidade em trabalho mecânico. A IA transforma eletricidade em algo que se parece, funcionalmente, com cognição.
Isso não significa que a IA “pensa” no sentido humano — essa é uma questão em aberto e profundamente debatida. Mas, do ponto de vista físico e econômico, a equação é direta: entra energia e dados, sai inferência. E é essa conversão, feita em escala colossal e a custos cada vez menores por unidade, que torna a IA uma das tecnologias mais transformadoras da nossa era.
A pergunta do título — “estamos transformando eletricidade em inteligência?” — tem, portanto, uma resposta técnica honesta: estamos transformando eletricidade em inferência computacional sofisticada o suficiente para ser útil como inteligência. Se isso é a mesma coisa que inteligência, deixamos para os filósofos. Mas o custo físico dessa transformação é real, mensurável e, agora, você o conhece.
Conclusão
Quando fazemos uma pergunta a uma IA, parece que estamos conversando com uma entidade inteligente. A interface é tão fluida, a resposta tão imediata, que é fácil esquecer o que existe por trás.
Mas agora você sabe.
Por trás de cada resposta existe uma infraestrutura colossal: data centers do tamanho de instalações industriais, redes globais de fibra óptica, milhares de processadores especializados, sistemas de refrigeração líquida, megawatts de energia elétrica e — em cada interação — trilhões de operações matemáticas executadas em segundos.
Você sabe que uma pergunta simples custa frações de watt-hora, mas que uma análise extensa pode custar cem vezes mais. Sabe que pensar, para uma máquina, é fazer contas em uma escala que nenhum ser humano conseguiria reproduzir em milhões de anos. Sabe que a IA é tanto um problema de software quanto de infraestrutura física, energia e engenharia industrial.
A verdadeira revolução da IA não está apenas nos modelos. Modelos brilhantes existem há anos. A revolução está na capacidade da humanidade de construir uma infraestrutura capaz de transformar energia, silício e matemática em conhecimento acessível — em poucos segundos, para centenas de milhões de pessoas, a um custo por consulta que despenca a cada ano.
Da próxima vez que você digitar uma pergunta e receber uma resposta instantânea, talvez valha a pena fazer uma pausa de um segundo. Naquele instante, em algum lugar do mundo, milhares de processadores acenderam, consumiram energia, geraram calor e executaram trilhões de cálculos — só para responder você.
Pensar tem um custo. E esse custo, finalmente, deixou de ser invisível.
Referências
ALTMAN, Sam. The Gentle Singularity. Blog pessoal de Sam Altman, jun. 2025. (Divulgação do consumo médio por consulta do ChatGPT: ~0,34 Wh e ~0,3 mL de água.) Disponível em: https://blog.samaltman.com/the-gentle-singularity. Acesso em: jun. 2026.
EPOCH AI. How much energy does ChatGPT use? Gradient Updates, 7 fev. 2025. Disponível em: https://epoch.ai/gradient-updates/how-much-energy-does-chatgpt-use. Acesso em: jun. 2026.
EPOCH AI. Over 30 AI models have been trained at the scale of GPT-4. Data Insights, jun. 2025. Disponível em: https://epoch.ai/data-insights/models-over-1e25-flop. Acesso em: jun. 2026.
GOOGLE. Measuring the environmental impact of delivering AI at Google scale. Google Cloud / arXiv:2508.15734, ago. 2025. Disponível em: https://arxiv.org/abs/2508.15734. Acesso em: jun. 2026.
HOFFMANN, Jordan et al. Training Compute-Optimal Large Language Models. arXiv, 2022. (Paper “Chinchilla”.) Disponível em: https://arxiv.org/abs/2203.15556. Acesso em: jun. 2026.
KAPLAN, Jared et al. Scaling Laws for Neural Language Models. arXiv, 2020. Disponível em: https://arxiv.org/abs/2001.08361. Acesso em: jun. 2026.
NVIDIA. What’s the Difference Between a CPU and a GPU? NVIDIA Blog. Disponível em: https://blogs.nvidia.com/blog/whats-the-difference-between-a-cpu-and-a-gpu/. Acesso em: jun. 2026.
NVIDIA. DGX B200 — The Foundation for Your AI Factory. NVIDIA Data Center. Disponível em: https://www.nvidia.com/en-us/data-center/dgx-b200/. Acesso em: jun. 2026.
RITCHIE, Hannah. What’s the carbon footprint of using ChatGPT or Gemini? [August 2025 update]. Sustainability by Numbers, 21 ago. 2025. Disponível em: https://hannahritchie.substack.com/p/ai-footprint-august-2025. Acesso em: jun. 2026.
VASWANI, Ashish et al. Attention Is All You Need. In: ADVANCES IN NEURAL INFORMATION PROCESSING SYSTEMS, 30., 2017. Anais… [S.l.]: NeurIPS, 2017. Disponível em: https://arxiv.org/abs/1706.03762. Acesso em: jun. 2026.