Como um modelo de Inteligência Artificial consegue escrever um texto coerente, criar uma imagem inédita, responder a uma pergunta complexa ou produzir código funcional em poucos segundos? A experiência é tão fluida que é fácil imaginar que há, do outro lado da tela, algo parecido com um pensamento. Mas não há. O que existe é uma sequência precisa de operações matemáticas e estatísticas, encadeadas em uma escala difícil de imaginar.
Este artigo percorre essa sequência do começo ao fim. A proposta não é ensinar a usar nenhuma ferramenta, e sim explicar a tecnologia por trás de todas elas. Vamos partir de uma frase simples e acompanhar sua transformação: primeiro em símbolos, depois em números, depois em vetores de centenas de dimensões; vamos ver como o modelo aprende a olhar para as relações entre as palavras através do mecanismo de atenção; entender a arquitetura Transformer que organiza tudo isso; e, por fim, descobrir como o sistema escolhe a próxima palavra com base em probabilidades — e como conceitos como entropia e temperatura governam essa escolha. No final, faremos uma ponte para as imagens, vendo por que a geração visual segue um caminho diferente, o da difusão.
O objetivo é ambicioso, mas concreto: que ao terminar a leitura você seja capaz de explicar, com suas próprias palavras, como funciona um modelo de IA generativa. Nenhum conhecimento prévio de programação ou matemática avançada é necessário. Basta curiosidade e disposição para seguir o raciocínio passo a passo.
A IA não vê palavras
Comece com uma frase trivial: “Eu gosto de café.”
Quando você, leitor humano, encontra essa frase, o processamento é instantâneo e invisível. Você reconhece quatro palavras — “Eu”, “gosto”, “de”, “café” —, entende que há um sujeito, um verbo que expressa preferência, e um objeto que é uma bebida. Você evoca, talvez sem perceber, o aroma, o calor da xícara, o ritual da manhã. Significado, para nós, é uma teia de associações sensoriais, emocionais e culturais construída ao longo de uma vida.
Para um modelo de linguagem, nada disso acontece. O computador não tem acesso ao conceito de café, nem à experiência de gostar de algo. O que ele recebe é uma cadeia de caracteres — uma sequência de símbolos sem significado intrínseco. E, num nível ainda mais fundamental, computadores não operam com letras nem com palavras: eles operam com números. Toda a engenharia da IA generativa nasce dessa restrição básica. Antes que qualquer “inteligência” possa acontecer, a linguagem precisa ser convertida em algo que uma máquina sabe manipular: quantidades.
Isso leva a uma reformulação importante do problema. A pergunta deixa de ser “como ensinar um computador a entender português?” e passa a ser “como transformar a linguagem em números de tal forma que as relações matemáticas entre esses números reflitam as relações de significado entre as palavras?”. Essa é, em essência, a pergunta que toda a área tenta responder. A jornada da frase “Eu gosto de café” até a resposta de um modelo é, antes de tudo, uma jornada de tradução: de símbolos para números, de números para vetores, e de vetores para relações.
Vale fixar a distinção, porque ela sustenta todo o resto. Para o humano, a frase é um conjunto de palavras carregadas de sentido. Para a máquina, ela começa como uma fila de símbolos, que logo vira uma fila de números, que por sua vez vira uma coleção de vetores em um espaço matemático. O “entendimento” do modelo, se quisermos chamá-lo assim, é inteiramente construído sobre essa fundação numérica.

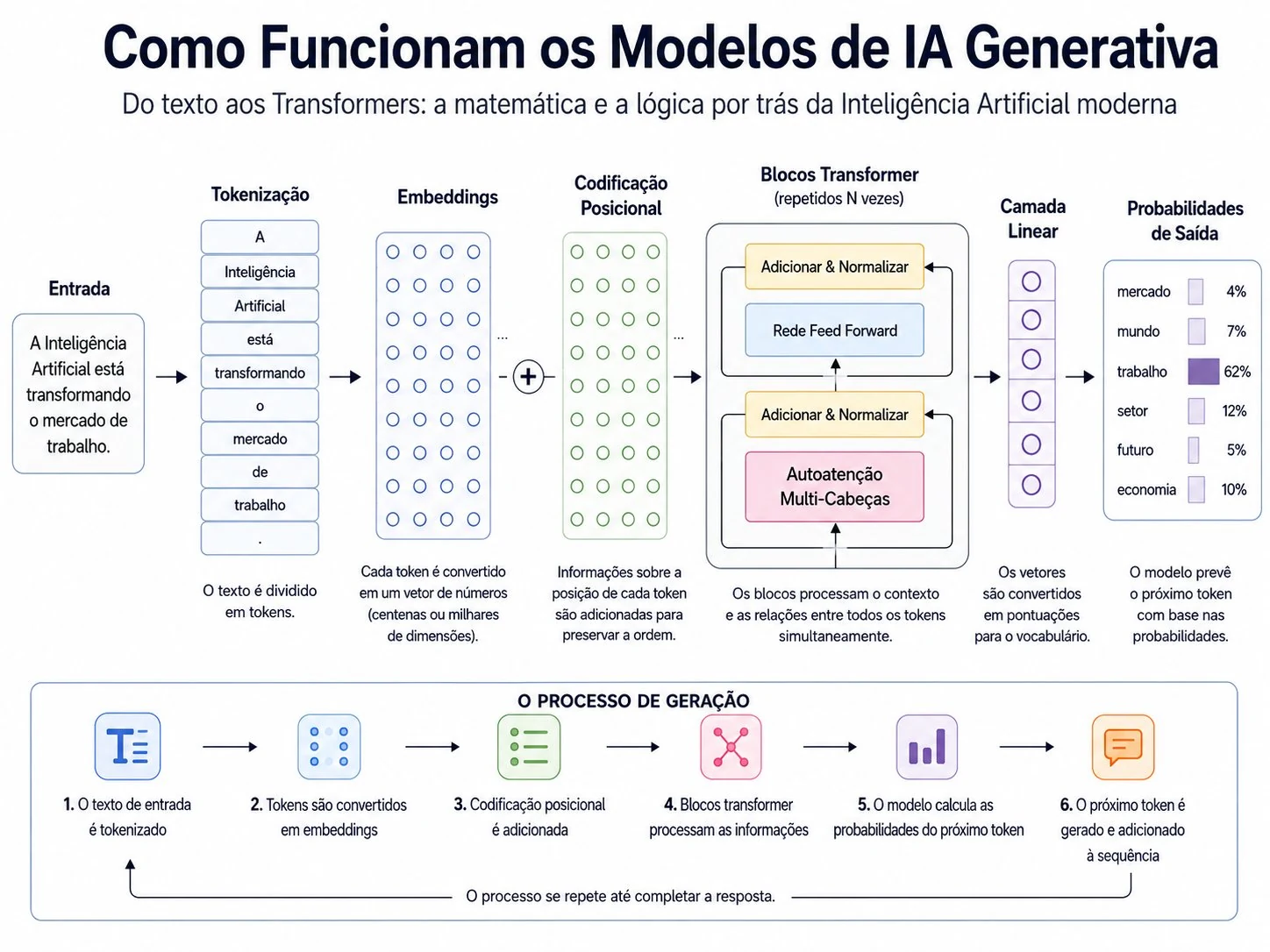
Se a primeira tarefa é transformar texto em números, o primeiro passo concreto é dividir o texto em pedaços. Esses pedaços se chamam tokens, e o processo de criá-los se chama tokenização.
A intuição inicial seria dividir por palavras. Tome a frase: “A Inteligência Artificial está transformando o mercado de trabalho.” A divisão por palavras produziria: “A”, “Inteligência”, “Artificial”, “está”, “transformando”, “o”, “mercado”, “de”, “trabalho”. Parece natural — mas os modelos modernos raramente trabalham exatamente assim. Em vez de palavras inteiras, eles costumam operar com subpalavras.
Por que fragmentar uma palavra? Há razões práticas fortes. Uma língua tem um número imenso de palavras possíveis, e novas surgem o tempo todo — gírias, nomes próprios, termos técnicos, palavras estrangeiras. Se cada palavra precisasse de uma entrada própria no “dicionário” do modelo, esse dicionário seria gigantesco e ainda assim incompleto: qualquer palavra nunca vista antes seria um beco sem saída. A solução é trabalhar com unidades menores e recombináveis. Uma palavra como “transformando” pode ser dividida em pedaços como “transform” e “ando”. Assim, mesmo uma palavra inédita pode ser representada pela combinação de fragmentos já conhecidos, e o modelo nunca fica completamente perdido diante de algo novo.
Esse “dicionário” de fragmentos conhecidos é o vocabulário do modelo — o conjunto fixo de todos os tokens que ele reconhece. Cada token do vocabulário tem um número de identificação único. A tokenização, portanto, é o ato de pegar um texto e convertê-lo na sequência de identificadores numéricos correspondentes. A frase sobre Inteligência Artificial deixa de ser uma cadeia de letras e passa a ser, para o modelo, uma sequência de números inteiros — cada um apontando para uma posição no vocabulário.
Vale notar dois detalhes que costumam surpreender quem encontra o conceito pela primeira vez. O primeiro é que os espaços e a pontuação também viram tokens, ou ficam embutidos neles: o ponto final da frase, por exemplo, é uma unidade que o modelo precisa representar. O segundo é que a contagem de tokens não corresponde à contagem de palavras. Uma palavra curta e comum pode ser um único token, enquanto uma palavra longa ou rara pode se desdobrar em vários. É por isso que, ao usar ferramentas de IA, o “tamanho” de um texto é medido em tokens, não em palavras — e textos em português tendem a consumir mais tokens que os mesmos textos em inglês, já que boa parte dos vocabulários foi otimizada para o inglês.
A tokenização é, então, a porta de entrada. Ela transforma linguagem em uma sequência ordenada de números. Mas esses números, sozinhos, ainda não carregam significado: o número que identifica “café” não é “maior” nem “menor” que o de “chá” em nenhum sentido útil. Ele é apenas um endereço. O significado entra na próxima etapa.
## Como palavras viram númerosVimos que cada token recebe um número de identificação. Mas esse número é só um rótulo — não diz nada sobre o que a palavra significa. O salto conceitual que torna a IA generativa possível está no próximo passo: converter cada token em um embedding.
Um embedding é uma lista de números — um vetor — que representa um token em um espaço de muitas dimensões. Em vez de um único número de identificação, cada token passa a ser descrito por centenas ou milhares de valores. Os modelos de linguagem atuais usam embeddings com dimensões que vão de algumas centenas a vários milhares de números por token. Cada um desses números pode ser pensado, de forma aproximada, como uma “coordenada” que posiciona o token em um espaço imenso e abstrato.
A ideia parece estranha à primeira vista. Por que descrever uma palavra com mil números? A resposta está no que esse arranjo permite. Quando representamos palavras como pontos em um espaço, podemos medir distâncias entre elas. E é aqui que a mágica acontece: durante o treinamento, o modelo ajusta esses vetores de modo que palavras com significados parecidos acabem ocupando posições próximas nesse espaço. “Gato” e “cachorro”, por compartilharem o contexto de animais domésticos, terminam vizinhos. “Rei” e “rainha” ficam próximos um do outro. “Café”, “chá” e “expresso” se agrupam numa mesma região. Palavras sem relação — “café” e “asfalto”, digamos — ficam distantes.
Essa propriedade tem um nome: similaridade semântica. O espaço onde os embeddings vivem é o espaço vetorial, e a distância entre conceitos nesse espaço passa a refletir a distância entre seus significados. O modelo não “sabe” o que é um gato, mas aprendeu que a palavra “gato” aparece em contextos parecidos com “cachorro” e diferentes de “tijolo”, e essa regularidade estatística fica codificada na posição dos vetores.
O exemplo mais célebre dessa estrutura é quase poético. Em muitos espaços de embeddings, é possível fazer operações aritméticas com significados. Pegue o vetor de “rei”, subtraia o vetor de “homem” e some o vetor de “mulher”: o ponto resultante cai muito perto do vetor de “rainha”. A relação “homem está para rei assim como mulher está para rainha” emerge como uma operação geométrica no espaço. Isso não foi programado por ninguém — emergiu do treinamento, da exposição a quantidades colossais de texto onde essas relações aparecem implicitamente o tempo todo. É a evidência mais elegante de que significado, capturado dessa forma, tem uma estrutura matemática.
Vale uma ressalva honesta: nem todas as relações semânticas são tão limpas quanto o exemplo “rei − homem + mulher”, e os espaços modernos são mais complexos do que esse caso ilustrativo sugere. Mas o princípio se mantém: ao transformar palavras em vetores e organizar esses vetores de modo que a geometria reflita o significado, criamos uma representação numérica da linguagem sobre a qual o cálculo pode operar. Os números deixaram de ser meros rótulos e passaram a carregar sentido — sentido posicional, relacional, mas sentido.
## O problema da ordem das palavrasHá um obstáculo que os embeddings, sozinhos, não resolvem: a ordem.
Considere duas frases feitas exatamente das mesmas palavras: “A empresa comprou o banco.” e “O banco comprou a empresa.” Os tokens são os mesmos. Os embeddings de cada palavra, isolados, são idênticos nos dois casos. E, no entanto, o significado é radicalmente diferente — em uma, a empresa é a compradora; na outra, é a comprada. A diferença está inteiramente na ordem em que as palavras aparecem.
Esse detalhe expõe uma limitação importante da arquitetura que veremos a seguir. Diferentemente de modelos mais antigos, que processavam o texto palavra por palavra, em sequência — e portanto “sabiam” naturalmente o que vinha antes e o que vinha depois —, a arquitetura Transformer processa todos os tokens de uma frase ao mesmo tempo, em paralelo. Esse paralelismo é uma das razões de sua eficiência e de seu sucesso, mas tem um custo: ao olhar para todos os tokens simultaneamente, o modelo perde a noção de sequência. Sem uma informação adicional, “A empresa comprou o banco” e “O banco comprou a empresa” seriam, para ele, indistinguíveis — apenas o mesmo conjunto de palavras embaralhado.
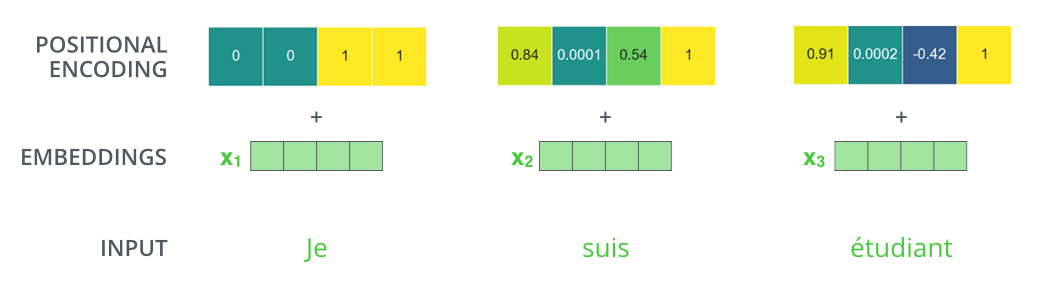
Vale uma nuance: nos modelos generativos do tipo decoder-only (como os GPTs), esse processamento paralelo é combinado com uma máscara causal, que impede o modelo de “olhar” para tokens futuros ao prever o próximo — preservando a lógica de gerar um token de cada vez. Mas isso não resolve, por si só, a questão da ordem. Para isso, a solução elegante chama-se codificação posicional (em inglês, positional encoding). A ideia é adicionar a cada embedding uma informação extra que indica a posição daquele token na sequência — primeiro, segundo, terceiro, e assim por diante. Em vez de um rótulo cru de posição, o método original usa padrões matemáticos baseados em funções senoidais de diferentes frequências, gerando, para cada posição, um vetor único que é somado ao embedding do token. O resultado é que o vetor final de cada token carrega, ao mesmo tempo, duas informações: o que a palavra é (vinda do embedding) e onde ela está na frase (vinda da codificação posicional).
Com isso, o modelo recupera a capacidade de distinguir as duas frases sobre a empresa e o banco. O token “empresa” na primeira posição carrega um sinal posicional diferente do token “empresa” na quinta posição, e essa diferença é suficiente para que o restante da arquitetura interprete corretamente quem comprou quem. A codificação posicional foi uma das contribuições do artigo que fundou os Transformers, e resolve, de forma compacta, um problema que à primeira vista parecia incompatível com o processamento paralelo.
Chegamos ao coração da história. Até aqui, temos uma frase convertida em vetores que carregam significado e posição. Falta o ingrediente que transformou tudo: o mecanismo de atenção (attention).
O problema que a atenção resolve é o do contexto. O significado de uma palavra quase nunca é fixo — ele depende das outras palavras ao redor. Pense na palavra “banco”. Em “sentei no banco da praça”, ela é um móvel. Em “fui ao banco sacar dinheiro”, é uma instituição financeira. Em “o banco de dados travou”, é uma estrutura de informação. A mesma sequência de letras, três significados distintos, decididos inteiramente pelo contexto. Para gerar linguagem coerente, um modelo precisa, de alguma forma, deixar que cada palavra “consulte” as demais e ajuste seu significado conforme a companhia.
A atenção é exatamente esse mecanismo de consulta. De maneira simplificada, para cada token da frase, o modelo calcula o quanto ele deve “prestar atenção” a cada um dos outros tokens — inclusive a si mesmo. Esses graus de atenção são pesos numéricos: quanto maior o peso entre dois tokens, mais um influencia a representação do outro. No exemplo do “banco”, ao processar essa palavra, o mecanismo atribui peso alto a “sacar” e “dinheiro” se eles estiverem presentes, empurrando o significado para o lado financeiro; ou a “praça” e “sentei”, empurrando para o lado do móvel. O contexto, antes implícito, vira um cálculo explícito de relevância entre todas as palavras.
A formulação técnica é conhecida como atenção por produto escalar escalonado (scaled dot-product attention), e organiza essa consulta em torno de três papéis que cada token assume simultaneamente: uma consulta (o que este token está procurando), uma chave (o que este token oferece) e um valor (a informação que ele carrega). O modelo compara a consulta de um token com as chaves de todos os outros para decidir os pesos, e então combina os valores de acordo com esses pesos. O resultado é uma nova representação de cada token, agora enriquecida pelo contexto de toda a frase. Não é preciso dominar a matemática para reter a ideia central: cada palavra é reescrita levando em conta todas as outras, na proporção da relevância de cada uma.
A razão de isso ter sido revolucionário tem dois lados. O primeiro é de qualidade: a atenção captura dependências de longo alcance com facilidade. Em uma frase longa, a palavra que esclarece o sentido de outra pode estar muito distante — e a atenção conecta as duas diretamente, sem precisar “carregar” a informação passo a passo ao longo de toda a sentença, como faziam as arquiteturas anteriores, que tendiam a esquecer o que estava longe. O segundo lado é de eficiência: como todos esses cálculos de relevância podem ser feitos em paralelo, o treinamento se torna muito mais rápido e escalável. O artigo que introduziu esse mecanismo demonstrou que ele, sozinho, bastava para superar os modelos anteriores em tradução automática — daí o título provocador, “Attention Is All You Need”. A atenção não era um complemento; era a peça central que faltava.

Em junho de 2017, um grupo de pesquisadores publicou o artigo que reorganizaria toda a área. Intitulado “Attention Is All You Need”, de autoria de Ashish Vaswani e colegas, o trabalho propunha uma arquitetura nova, batizada de Transformer, construída inteiramente em torno do mecanismo de atenção — sem as redes recorrentes ou convolucionais que dominavam até então. A proposta era ousada: descartar tudo o que se considerava essencial e apostar que a atenção, sozinha, bastava. A aposta venceu, e o Transformer se tornou a base de praticamente todos os grandes modelos de linguagem que vieram depois, do GPT ao Claude e ao Gemini.
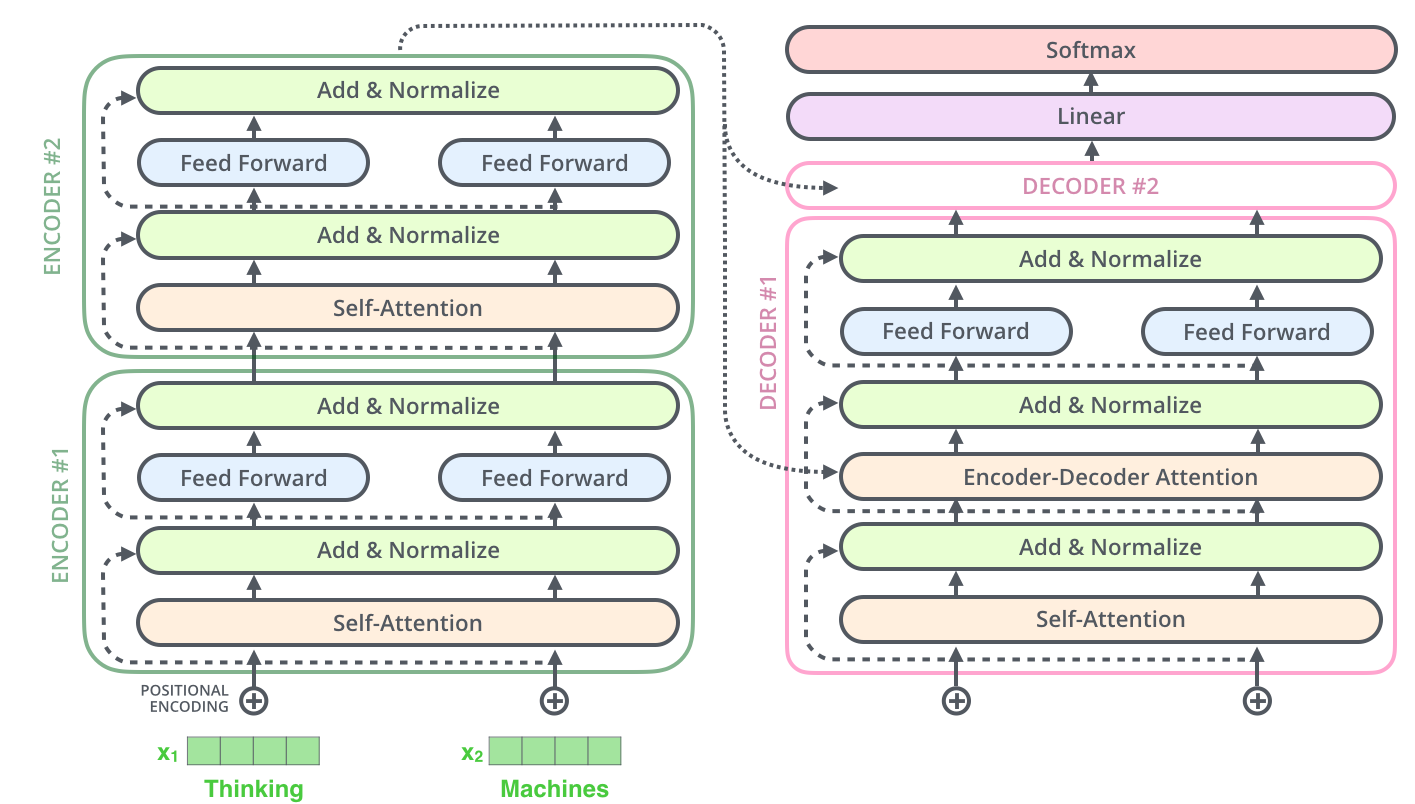
A arquitetura original tinha duas grandes partes: um encoder (codificador) e um decoder (decodificador). O encoder tem a função de ler e compreender a sequência de entrada, transformando-a em uma representação rica de contexto. O decoder usa essa representação para gerar a sequência de saída, um token de cada vez. Essa divisão fazia sentido para a tarefa original do artigo, a tradução automática: o encoder “entende” a frase em inglês, o decoder “produz” a frase em alemão. Vale notar que muitos modelos de geração de texto atuais usam apenas a parte do decoder, adaptando a ideia original — mas os componentes fundamentais permanecem os mesmos.
Dentro de cada bloco, dois elementos se repetem. O primeiro é a autoatenção (self-attention) — o mecanismo que vimos na seção anterior, permitindo que cada token consulte os demais. Na prática, os Transformers usam uma variação chamada atenção de múltiplas cabeças (multi-head attention): em vez de calcular a atenção uma única vez, o modelo a calcula várias vezes em paralelo, cada “cabeça” aprendendo a focar em um tipo diferente de relação. Uma cabeça pode se especializar em relações gramaticais, outra em referências entre pronomes e substantivos, outra em proximidade temática. As várias perspectivas são então combinadas, dando ao modelo uma visão mais rica das relações na frase.
O segundo elemento é a rede feed-forward (feed-forward network): após a etapa de atenção, a representação de cada token passa por uma pequena rede neural que a processa individualmente, refinando a informação. Se a atenção é a etapa em que os tokens “conversam” entre si, a rede feed-forward é a etapa em que cada token “pensa” sozinho sobre o que acabou de absorver do contexto.
Costurando tudo, há dois mecanismos discretos mas essenciais, que aparecem como “Adicionar & Normalizar” nos diagramas. As conexões residuais somam a entrada de cada etapa à sua saída, criando atalhos que ajudam a informação a fluir e permitem empilhar muitas camadas sem que o sinal se degrade. A normalização mantém os números em uma faixa estável, o que torna o treinamento mais confiável. Graças a esses recursos, os blocos do Transformer podem ser empilhados — repetidos muitas vezes em sequência —, e é justamente essa profundidade, combinada com a escala dos dados e dos parâmetros, que dá aos modelos modernos sua capacidade. Cada bloco refina um pouco mais a compreensão; dezenas deles, empilhados, produzem a representação sofisticada que sustenta a geração de texto.
Toda a maquinaria que descrevemos — tokens, embeddings, posição, atenção, blocos Transformer — existe para servir a um objetivo surpreendentemente simples de enunciar: prever o próximo token. Um modelo de linguagem generativo, em sua essência, é uma máquina de completar sequências. Dado um trecho de texto, ele estima qual token tem mais probabilidade de vir em seguida. Depois acrescenta esse token ao texto e repete o processo, prevendo o próximo, e o próximo, gerando a resposta uma peça de cada vez.
Vejamos isso em ação. Imagine que o modelo recebeu o início de frase: “O sol nasce todos os dias no…”. Após processar esse trecho por toda a arquitetura, a camada final do modelo produz, para cada token possível do seu vocabulário, uma pontuação. Essas pontuações são então convertidas em uma distribuição de probabilidade — um conjunto de números, entre zero e um, que somam exatamente um e indicam a chance de cada token ser a continuação. No nosso exemplo, “leste” ou “horizonte” receberiam probabilidades altas; “oceano” e “céu”, probabilidades intermediárias; e tokens sem relação, como “abacaxi” ou “guitarra”, probabilidades muito baixas. Dependendo da estratégia de geração usada, esses tokens improváveis podem ainda participar do sorteio ou ser filtrados antes da escolha final.
A etapa que converte as pontuações brutas em probabilidades tem um papel central, e é feita por uma função chamada softmax. Não é preciso conhecer sua fórmula para entender o que ela faz: ela pega uma lista de números quaisquer e os transforma em uma distribuição de probabilidade bem-comportada, ampliando as diferenças (o token com maior pontuação recebe uma fatia proporcionalmente maior) e garantindo que tudo some um. É a ponte entre o cálculo interno do modelo e uma escolha probabilística concreta.
Tendo a distribuição em mãos, o modelo precisa escolher um token — e aqui entra a amostragem (sampling). A estratégia mais simples seria sempre pegar o token de maior probabilidade. Mas isso tornaria o texto rígido e repetitivo. Em vez disso, os sistemas costumam sortear o próximo token respeitando a distribuição: tokens mais prováveis têm mais chance de serem escolhidos, mas os menos prováveis ainda têm alguma chance. É esse elemento de sorteio que dá ao texto gerado sua variedade e fluidez — e a razão de o mesmo prompt poder gerar respostas diferentes a cada vez.
Há uma consequência conceitual profunda nisso, e vale enunciá-la sem rodeios: o modelo não “sabe” a resposta. Um modelo de linguagem, por si só, não funciona como um banco de dados de verdades verificadas: ele estima, com base nos padrões estatísticos aprendidos durante o treinamento, qual continuação é mais provável. Em sistemas mais avançados, esse modelo pode ser combinado com busca na web, ferramentas, bases externas e mecanismos de verificação — mas isso já é uma camada adicional, construída ao redor do modelo, e não o modelo em si. Quando acerta um fato, é porque aquela continuação correta era estatisticamente dominante nos dados. Quando erra — quando “alucina”, produzindo uma informação falsa com tom de confiança —, é porque uma continuação plausível, mas incorreta, recebeu probabilidade alta. Entender isso é entender a natureza fundamental e os limites desses sistemas: eles são geradores de continuações prováveis, não oráculos de verdade.
O papel da entropia
Para compreender por que e como o modelo lida com a incerteza, precisamos recuar quase oitenta anos, até um trabalho que fundou um campo inteiro: a teoria da informação. Em 1948, o matemático e engenheiro Claude Shannon publicou, no Bell System Technical Journal, o artigo “A Mathematical Theory of Communication”. Nele, Shannon propôs uma forma de medir, em termos matemáticos precisos, a quantidade de informação contida em uma mensagem — e introduziu o conceito que nos interessa aqui: a entropia.
No uso de Shannon, entropia é uma medida de incerteza ou imprevisibilidade. Quanto mais incerto é o resultado de um evento, maior sua entropia, e mais informação é necessária para descrevê-lo. Um exemplo torna isso concreto. Considere uma moeda. Se ela é honesta — 50% de chance para cada lado —, o resultado de um lançamento é maximamente imprevisível: você não tem como saber o que vai sair. Essa situação tem o máximo de entropia. Agora imagine uma moeda viciada que cai em cara 99% das vezes. O resultado é quase certo, quase previsível, e a entropia é baixa. No extremo, uma moeda com duas caras tem entropia zero: não há incerteza alguma, o resultado é sempre conhecido de antemão.
A intuição se transfere diretamente para a linguagem, e foi o próprio Shannon quem fez essa ponte, em um trabalho posterior sobre a previsibilidade do inglês escrito. Algumas continuações de texto são de baixa entropia: depois de “São Paulo é a maior cidade do…”, a palavra “Brasil” é tão provável que há pouca incerteza — a distribuição de probabilidade é concentrada, “afiada”, com um pico dominante. Outras continuações são de alta entropia: depois de “Ela abriu a porta e viu…”, quase qualquer coisa poderia vir — “um cachorro”, “o mar”, “ninguém”, “uma carta” —, e a distribuição é espalhada, com muitos tokens dividindo probabilidades parecidas.
A entropia, portanto, descreve o formato da distribuição de probabilidade que o modelo produz a cada passo. Uma distribuição de baixa entropia significa que o modelo está “confiante” — há um ou poucos candidatos dominantes. Uma de alta entropia significa que o modelo está diante de muitas continuações igualmente plausíveis. Essa medida não é um detalhe acadêmico: ela está no centro de como controlamos o comportamento dos modelos generativos, como veremos a seguir. A formulação de Shannon — uma soma sobre todos os resultados possíveis, ponderando cada probabilidade pelo seu próprio logaritmo — é a base matemática que permite quantificar tudo isso, e segue, mais de sete décadas depois, sustentando a tecnologia que conversa conosco hoje.

{kind=link}
Se a entropia descreve o formato natural da distribuição de probabilidade, a temperatura é o controle que nos permite ajustar esse formato deliberadamente. É um dos parâmetros mais importantes — e mais mal compreendidos — no uso prático de modelos generativos.
A temperatura é um número que reescala as probabilidades antes da amostragem, tornando a distribuição mais “afiada” ou mais “achatada”. Quando a temperatura é baixa, as diferenças entre os tokens são amplificadas: o token mais provável fica ainda mais dominante, e os improváveis quase desaparecem. O efeito é um texto mais previsível, conservador e determinístico — o modelo tende a sempre escolher as continuações mais seguras. Para tarefas que exigem precisão, como responder a uma pergunta factual ou gerar código, temperaturas baixas costumam ser preferíveis.
Quando a temperatura é alta, ocorre o oposto: as diferenças entre os tokens são comprimidas, achatadas. Tokens menos prováveis ganham uma chance maior de serem sorteados, e a distribuição se aproxima de algo mais uniforme. O resultado é um texto mais variado, surpreendente e criativo — mas também mais propenso a divagar, fugir do tema ou produzir incoerências. Para tarefas criativas, como gerar ideias, escrever ficção ou explorar variações, temperaturas mais altas podem ser desejáveis.
Um exemplo concreto ajuda. Suponha o início “A receita perfeita para um dia de chuva é um bom…”. Com temperatura baixa, o modelo quase certamente completaria com algo como “livro” ou “filme” — as continuações mais prováveis e seguras. Com temperatura alta, ele poderia escolher “cobertor”, “café”, “silêncio” ou até continuações mais inusitadas, porque tokens de probabilidade média e baixa passaram a ter chances reais de serem sorteados. Nenhuma das opções é “errada”; o que muda é o grau de ousadia na escolha.
Matematicamente, a temperatura atua dividindo as pontuações dos tokens por seu valor antes de aplicar a função softmax. Dividir por um número menor que um (temperatura baixa) acentua as diferenças; dividir por um número maior que um (temperatura alta) as suaviza. Mas o essencial não é a fórmula, e sim a relação com o que vimos antes: a temperatura é, na prática, um controle de entropia. Temperatura baixa reduz artificialmente a entropia da distribuição, concentrando as apostas; temperatura alta aumenta a entropia, espalhando-as. É o botão que regula o quanto o modelo deve se arriscar — e entender isso permite usar os modelos com muito mais intenção e controle.
## Como a IA gera imagensTudo o que vimos até aqui descreve modelos de linguagem — sistemas que trabalham com texto, prevendo um token após o outro. Mas a IA generativa também cria imagens, e o mecanismo por trás disso é fundamentalmente diferente. Enquanto a geração de texto é sequencial e probabilística token a token, uma das abordagens mais importantes e populares para geração de imagens segue um princípio chamado difusão (diffusion) — especialmente nos modelos de difusão latente, que inspiraram o Stable Diffusion.
A ideia da difusão é, à primeira vista, contraintuitiva: ela aprende a criar removendo ruído. O processo de treinamento funciona em duas direções. Na direção “para a frente”, o sistema pega uma imagem real e vai adicionando ruído gradualmente, passo a passo, até que a imagem se torne pura estática aleatória — como uma televisão fora do ar. O ponto crucial vem na direção inversa: o modelo é treinado para reverter esse processo, ou seja, para prever e remover o ruído etapa por etapa. Essa remoção gradual de ruído é o que se chama, em inglês, de denoising. Tendo aprendido a limpar ruído de imagens reais durante o treinamento, o modelo adquire uma capacidade notável: a de partir de um campo de ruído totalmente aleatório e, removendo ruído passo a passo, “esculpir” uma imagem coerente que nunca existiu.
É como se um escultor tivesse aprendido a olhar para um bloco de mármore e enxergar, dentro do caos da pedra bruta, a estátua que pode emergir — e então retirasse o excesso até revelá-la. O modelo de difusão faz o equivalente com ruído: começa do caos e, a cada passo de denoising, aproxima-se de uma imagem estruturada. Quando há um texto de comando (“um gato astronauta em estilo aquarela”), esse comando guia o processo, orientando para que tipo de imagem o ruído deve convergir.
A inovação que tornou esse processo eficiente e acessível veio com o artigo “High-Resolution Image Synthesis with Latent Diffusion Models”, de Robin Rombach e colegas, publicado em 2021 e apresentado na conferência CVPR de 2022 — o trabalho que está na base do Stable Diffusion. A contribuição central foi mover o processo de difusão para o que se chama de espaço latente (latent space). Aplicar a difusão diretamente nos pixels de uma imagem de alta resolução é extremamente custoso — são milhões de pixels para processar a cada passo. A sacada dos autores foi primeiro comprimir a imagem para uma representação latente muito menor, que preserva a informação semântica essencial e descarta detalhes imperceptíveis, e então rodar todo o processo de difusão nesse espaço comprimido e eficiente. Só ao final a representação latente é expandida de volta em uma imagem de alta resolução.
Essa mudança teve um impacto enorme: reduziu drasticamente o custo computacional, tornando possível gerar imagens de alta qualidade em hardware acessível, e abriu caminho para a explosão de ferramentas de geração de imagem que vimos a partir de então. O mesmo artigo também introduziu o uso de camadas de atenção cruzada (cross-attention) para conectar o comando de texto ao processo de geração visual — um elo direto, e elegante, com o mecanismo de atenção que move os modelos de linguagem. Texto e imagem, no fim, compartilham mais fundamentos matemáticos do que sua aparência sugere.
## ConclusãoPercorremos a jornada inteira, da frase digitada à resposta gerada. Vale recompô-la em uma frase só, agora que cada peça tem nome. O texto é dividido em tokens; cada token vira um embedding, um vetor em um espaço de muitas dimensões onde a geometria reflete o significado; a codificação posicional acrescenta a noção de ordem; o mecanismo de atenção deixa cada palavra consultar todas as outras e ajustar seu sentido ao contexto; os blocos do Transformer empilham essas operações em profundidade; e, ao final, o modelo produz uma distribuição de probabilidade sobre o próximo token, da qual sorteia uma continuação, regulada por conceitos como entropia e temperatura. Para imagens, o caminho é o da difusão: criar removendo ruído, de forma eficiente, no espaço latente.
Há uma conclusão maior que atravessa tudo isso, e que vale guardar. Modelos generativos não pensam da forma como seres humanos pensam. Eles não compreendem, não acreditam, não sabem — não no sentido que damos a essas palavras. O que eles fazem é transformar texto, imagens, sons ou vídeos em representações matemáticas, calcular relações estatísticas de uma complexidade imensa e usar probabilidades para gerar novas saídas. A fluência impressionante que vemos na tela é o produto dessa engenharia, não de uma mente.
Reconhecer isso não diminui a tecnologia — pelo contrário, é o que permite usá-la bem. Quem entende que o modelo gera continuações prováveis, e não verdades, sabe por que ele às vezes inventa fatos com confiança e por que vale a pena verificar o que ele produz. Quem entende o papel da temperatura sabe quando pedir precisão e quando pedir criatividade. Quem entende que tudo começa na conversão de linguagem em números compreende por que o contexto que fornecemos importa tanto. Foi a combinação entre tokens, embeddings, mecanismos de atenção, Transformers, probabilidade e aprendizado em escala colossal que tornou possível a geração atual de sistemas de IA. Compreender essa combinação é deixar de ver a IA como mágica — e passar a vê-la como o que ela é: uma das construções matemáticas mais notáveis da nossa época, com poderes reais e limites igualmente reais.
Referências
ALAMMAR, Jay. The Illustrated Transformer. 2018. Disponível em: https://jalammar.github.io/illustrated-transformer/. Acesso em: jun. 2026.
HUGGING FACE. Summary of the tokenizers. Documentação Transformers. Disponível em: https://huggingface.co/docs/transformers/tokenizer_summary. Acesso em: jun. 2026.
HUGGING FACE. Text generation strategies. Documentação Transformers. Disponível em: https://huggingface.co/docs/transformers/generation_strategies. Acesso em: jun. 2026.
OPENAI. Tokenizer. OpenAI Platform. Disponível em: https://platform.openai.com/tokenizer. Acesso em: jun. 2026.
RADFORD, Alec; NARASIMHAN, Karthik; SALIMANS, Tim; SUTSKEVER, Ilya. Improving Language Understanding by Generative Pre-Training. OpenAI, 2018. Disponível em: https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf. Acesso em: jun. 2026.
ROMBACH, Robin; BLATTMANN, Andreas; LORENZ, Dominik; ESSER, Patrick; OMMER, Björn. High-Resolution Image Synthesis with Latent Diffusion Models. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022, p. 10684-10695. arXiv:2112.10752. Disponível em: https://arxiv.org/abs/2112.10752. Acesso em: jun. 2026.
SHANNON, Claude E. A Mathematical Theory of Communication. Bell System Technical Journal, v. 27, n. 3, p. 379-423, jul. 1948. DOI: 10.1002/j.1538-7305.1948.tb01338.x. Disponível em: https://onlinelibrary.wiley.com/doi/10.1002/j.1538-7305.1948.tb01338.x. Acesso em: jun. 2026.
TENSORFLOW. Embedding Projector. Google Research. Disponível em: https://projector.tensorflow.org/. Acesso em: jun. 2026.
VASWANI, Ashish; SHAZEER, Noam; PARMAR, Niki; USZKOREIT, Jakob; JONES, Llion; GOMEZ, Aidan N.; KAISER, Łukasz; POLOSUKHIN, Illia. Attention Is All You Need. In: Advances in Neural Information Processing Systems (NeurIPS), 2017. arXiv:1706.03762. Disponível em: https://arxiv.org/abs/1706.03762. Acesso em: jun. 2026.