Introdução
Se a Inteligência Artificial já consegue conversar, pesquisar, programar, analisar documentos e executar tarefas complexas em sequência, estamos diante de uma nova geração de softwares — ou de uma nova camada da própria internet?
A pergunta parece simples. A resposta, não.
Para a maioria das pessoas, a IA se resume ao ChatGPT, ao Claude ou ao Gemini: caixas de texto inteligentes onde você digita uma pergunta e recebe uma resposta. É uma experiência impressionante, sem dúvida. Mas reduzir a Inteligência Artificial moderna a essa interface é como acreditar que a internet é o Google: você está vendo apenas a ponta do iceberg.
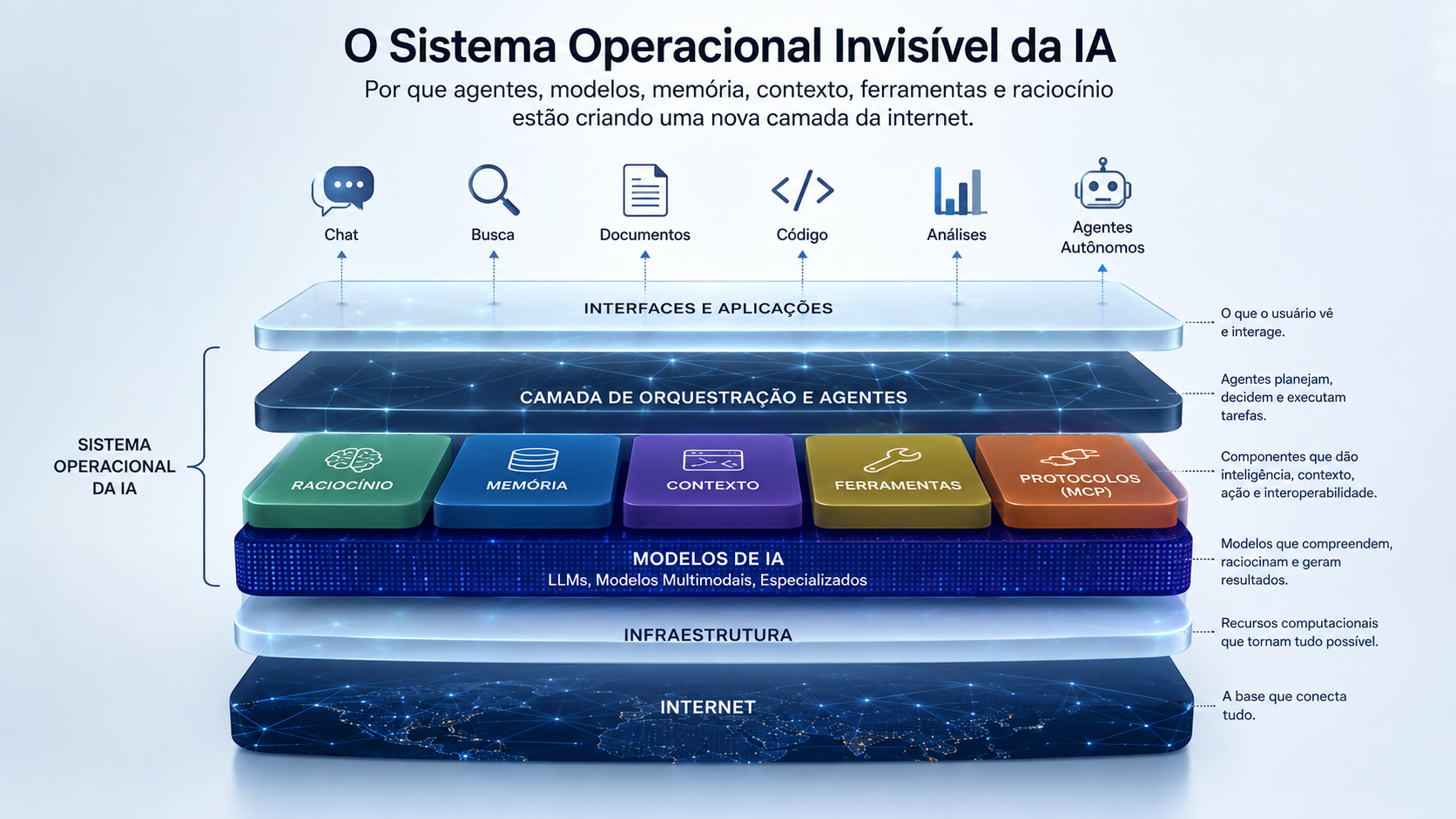
Por trás de cada conversa com um modelo de linguagem existe uma arquitetura crescente de componentes interdependentes — sistemas de memória, mecanismos de raciocínio, integrações com ferramentas externas, protocolos de comunicação e frameworks de orquestração. Uma infraestrutura que, de forma silenciosa e incremental, está se tornando tão fundamental quanto os sistemas operacionais, os navegadores ou a computação em nuvem.
Este artigo tem um objetivo preciso: mostrar que a IA moderna não é um chatbot sofisticado. Ela está se tornando, tecnicamente, um novo sistema operacional para a internet.
Um sistema que você não vê, mas que já está executando processos, gerenciando recursos, coordenando agentes e traduzindo intenções humanas em ações computacionais. Um sistema que conecta modelos de linguagem a memória, contexto, ferramentas, APIs, bancos de dados e outros agentes.
Chamamos esse fenômeno de o sistema operacional invisível da IA.
A grande ilusão: IA não é um chatbot
Existe um padrão curioso na história da tecnologia: quando uma inovação transformadora emerge, a maioria das pessoas a conhece pela sua interface mais superficial — não pela sua infraestrutura.
Quando a internet chegou ao grande público nos anos 1990, a maioria das pessoas a enxergava como “aquele negócio de e-mail”. Ninguém estava pensando em TCP/IP, DNS ou protocolos HTTP. A interface era o e-mail. A infraestrutura era outra coisa inteiramente.
Quando os smartphones chegaram, as pessoas os descreviam como “telefones com aplicativos”. Mas o que estava acontecendo era a criação de uma plataforma computacional completamente nova — com sensores, GPS, câmeras, sistemas operacionais móveis e App Stores. A interface era o telefone. A infraestrutura era outra coisa.
Com a IA, o padrão se repete.
A interface visível é o chatbot. Você abre um navegador, digita uma pergunta, recebe uma resposta. Intuitivo, rápido, impressionante. Mas o que acontece por baixo dessa interface é muito mais sofisticado.
O chatbot é a janela de um navegador. O verdadeiro sistema é o que acontece antes, durante e depois da resposta aparecer na tela.
Quando você envia uma mensagem para um sistema moderno de IA, dependendo da arquitetura, uma cadeia invisível de eventos é disparada: a mensagem é processada e contextualizada; o sistema verifica se precisa buscar informações externas; decide se deve consultar um banco de dados; avalia se precisa acionar uma ferramenta, uma API ou um agente especializado; orquestra essa cadeia de ações; monitora os resultados; e só então formula uma resposta — que pode ser texto, dados estruturados, código executável, ou até uma série de ações automáticas.
Isso não é um chatbot. É um sistema computacional completo.
A diferença fundamental: um chatbot converte texto em texto. Um sistema moderno de IA converte intenção em ação.
Os modelos são apenas o motor
Para entender a nova infraestrutura da IA, é preciso começar pelo componente mais famoso — e mais mal compreendido: o modelo de linguagem.
Um Large Language Model (LLM) é uma rede neural de grande escala treinada para prever o próximo token em uma sequência de texto. Tecnicamente, ele é baseado na arquitetura transformer — descrita originalmente em 2017 no artigo seminal Attention Is All You Need, de Vaswani e colaboradores no Google. O mecanismo central dessa arquitetura, chamado de atenção (self-attention), permite que o modelo pese dinamicamente a relevância de diferentes partes do texto de entrada ao gerar cada novo token.
Na prática: você fornece uma entrada (o prompt) e o modelo calcula a distribuição de probabilidade sobre todos os tokens possíveis, escolhendo os mais prováveis para compor a resposta — um token de cada vez, em um processo que pode gerar centenas ou milhares de palavras em segundos.
Isso é o modelo. Apenas isso.
E aqui está o ponto central que a maioria das pessoas não percebe: o modelo, por si só, não faz nada além de gerar texto. Ele não navega na internet. Não executa código. Não lembra de conversas anteriores. Não acessa bancos de dados. Não envia e-mails. Não coordena outros sistemas.
A analogia mais precisa é o motor de um automóvel.
Um motor a combustão é uma máquina extraordinária — converte energia química em energia mecânica com eficiência notável. Mas o motor sozinho não leva ninguém a lugar nenhum. Você precisa de transmissão, direção, freios, combustível, painel de controle, rodas e de alguém que saiba para onde ir. O motor é um componente fundamental, mas apenas um componente.
LLMs modernos — como os da família GPT-4 e GPT-4o da OpenAI, Claude da Anthropic, Gemini do Google DeepMind ou Llama da Meta — são motores extraordinariamente poderosos. Mas o sistema que os torna realmente úteis é o que existe ao redor deles: a memória, o contexto, as ferramentas, os protocolos de comunicação e os sistemas de orquestração.
É esse sistema que estamos investigando neste artigo.
O problema da memória
Imagine que você começa cada manhã sem nenhuma memória do dia anterior. Você conhece sua profissão, sabe falar português, domina todas as suas habilidades técnicas — mas não lembra de nada do que aconteceu ontem. Nenhuma conversa, nenhuma decisão, nenhum compromisso.
Essa é, grosso modo, a condição padrão de um modelo de linguagem.
Os LLMs têm conhecimento do mundo — adquirido durante o treinamento em enormes volumes de texto. Mas não têm memória persistente entre sessões. Cada nova conversa começa do zero. Quando você fecha o chat e abre de novo, o modelo não sabe quem você é, o que discutiram ou o que foi decidido.
O mecanismo que simula memória durante uma conversa é chamado de janela de contexto (context window): o bloco de texto que o modelo pode “ver” ao mesmo tempo, incluindo todo o histórico da sessão atual. Modelos modernos têm janelas de contexto expressivas — GPT-4 Turbo suporta até 128.000 tokens; Claude 3.5 da Anthropic opera com até 200.000 tokens. Um token equivale, aproximadamente, a três quartos de uma palavra em inglês.
Mas a janela de contexto é memória de trabalho — não memória de longo prazo. Quando ela se esgota ou a sessão termina, tudo é perdido.
Esse problema gerou toda uma área de pesquisa e engenharia. A literatura técnica distingue, em geral, quatro tipos de memória relevantes para sistemas agentivos:
Memória in-context (sensorial): o que está na janela de contexto atual — histórico de mensagens, documentos carregados, resultados de ferramentas.
Memória episódica (curto prazo): informações sobre interações recentes, armazenadas externamente e recuperadas no início de cada sessão — um resumo das últimas conversas, por exemplo.
Memória semântica (longo prazo): conhecimento factual sobre o usuário, suas preferências, histórico e objetivos — armazenado em bancos de dados vetoriais ou sistemas de memória persistente.
Memória procedural: como executar determinadas tarefas — incorporada ao treinamento do modelo ou às instruções do sistema.
Empresas e frameworks estão desenvolvendo soluções concretas para cada um desses tipos. Em 2024, a OpenAI lançou funcionalidade de memória no ChatGPT, permitindo que o modelo retenha informações entre sessões. A Anthropic implementou recursos similares no Claude. O framework LangChain oferece abstrações padronizadas para memória de curto e longo prazo em agentes.
O ponto crítico: um sistema de IA sem memória persistente é como um funcionário que esquece tudo o que aprendeu ao sair do escritório. Funciona para tarefas pontuais, mas é incapaz de aprender, adaptar-se e evoluir ao longo do tempo. A memória está se tornando um dos componentes centrais — e mais competitivos — da nova infraestrutura.
O contexto é o novo sistema operacional
Se a memória define o que o sistema lembra, o contexto define o que ele sabe no momento exato em que age.
Contexto, em sistemas de IA modernos, não é apenas o histórico da conversa. É o conjunto completo de informações disponíveis ao modelo durante a geração de uma resposta: mensagens anteriores, documentos carregados, resultados de buscas, saídas de ferramentas, instruções do sistema, exemplos de uso e dados recuperados de bases externas.
Há alguns anos, os modelos de linguagem eram sistemas fechados: só conheciam o que foi ensinado durante o treinamento. Isso criava limitações evidentes — o modelo não sabia o que aconteceu depois da data de corte do treinamento, não tinha acesso a documentos privados e não conseguia consultar dados em tempo real.
A solução que mudou essa dinâmica foi o RAG — Retrieval-Augmented Generation.
Descrita no artigo seminal de Lewis et al., publicado em 2020 na NeurIPS (Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks), a técnica é conceitualmente elegante: antes de gerar uma resposta, o sistema recupera (retrieves) informações relevantes de uma base de conhecimento externa — documentos, artigos, registros de banco de dados — e os insere no contexto que o modelo recebe.
O resultado: o modelo passa a ter acesso a informações que não faziam parte do seu treinamento, sem precisar ser retreinado.
RAG democratizou a possibilidade de conectar modelos de linguagem a bases de conhecimento privadas. Hoje, sistemas corporativos usam RAG para construir assistentes que conhecem políticas internas da empresa, manuais técnicos, histórico de clientes e catálogos de produtos — tudo sem expor dados a terceiros e sem o custo e a complexidade do fine-tuning.
Mas há algo mais profundo acontecendo aqui.
À medida que os sistemas de contexto evoluem — incorporando RAG, memória persistente, resultados de ferramentas em tempo real e raciocínio estruturado —, o contexto está se tornando o principal determinante da qualidade da resposta. Não o modelo em si.
Dois sistemas usando o mesmo modelo base podem produzir resultados radicalmente diferentes dependendo do contexto que recebem. Um assistente médico com RAG alimentado por literatura clínica atualizada e protocolos hospitalares específicos vai performar muito melhor do que o mesmo modelo sem esse contexto — mesmo que o modelo base seja idêntico.
Isso levou à formulação de uma tese que está ganhando espaço entre engenheiros de sistemas de IA:
“Quem controla o contexto controla a inteligência.”
O contexto — bem construído, bem estruturado, bem recuperado — é, hoje, o principal ativo de diferenciação em sistemas de IA corporativos. Controlá-lo tornou-se uma competência estratégica.
Ferramentas: quando a IA deixa de apenas responder
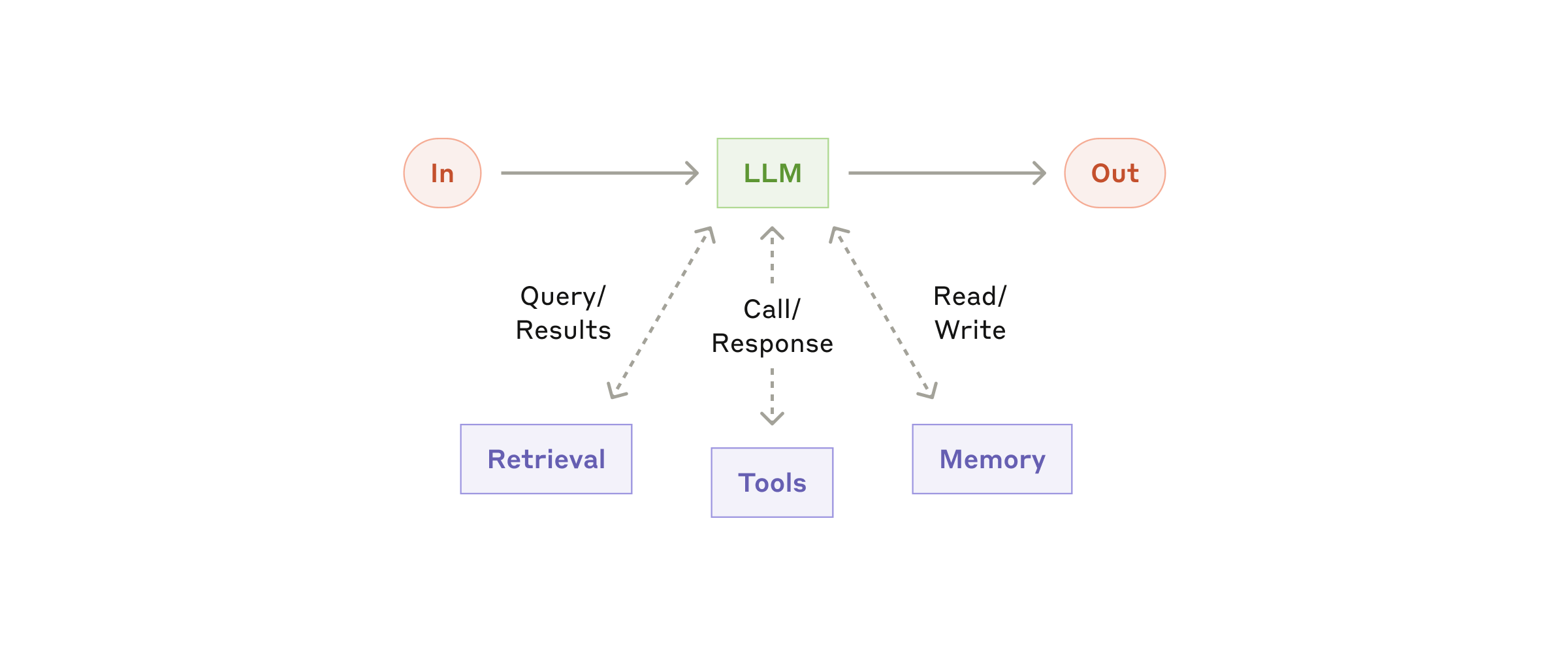
Até aqui, descrevemos um sistema que pensa, lembra e contextualiza — mas que ainda responde com texto. O próximo salto qualitativo acontece quando o sistema começa a agir.
Em sistemas modernos de IA, ferramentas (tools) são funções externas que o modelo pode invocar durante seu processo de raciocínio. Em vez de apenas gerar texto, o modelo pode decidir chamar uma calculadora, buscar informações na web, consultar um banco de dados, enviar um e-mail, criar um arquivo, executar código, fazer uma requisição a uma API ou acionar qualquer outro serviço externo.
O mecanismo técnico por trás disso é chamado de Function Calling — ou, nas implementações mais recentes, Tool Use.
O funcionamento é o seguinte: ao configurar um sistema de IA, o desenvolvedor define um conjunto de ferramentas disponíveis, descrevendo em linguagem natural o que cada uma faz, quais parâmetros aceita e o que retorna. O modelo, ao receber uma pergunta que exige dados ou ações externas, decide — de forma autônoma — qual ferramenta invocar, com quais parâmetros, e como interpretar o resultado.
A OpenAI introduziu Function Calling formalmente em junho de 2023. A Anthropic implementou Tool Use no Claude. O Google Gemini tem suporte nativo a ferramentas. Hoje, praticamente todos os modelos de fronteira suportam alguma forma de interação com ferramentas externas.
Exemplos concretos de como isso funciona em sistemas reais:
Um assistente financeiro consulta preços de ações em tempo real antes de responder sobre portfólios. Um agente de atendimento ao cliente verifica o status de um pedido no ERP antes de responder ao cliente. Um assistente de programação executa o código gerado, verifica se funciona e corrige erros antes de apresentar a solução. Um pesquisador automático navega em páginas da web, extrai informações e as consolida em um relatório estruturado. Um agente de marketing gera variações de copy, registra os resultados de testes e reporta qual versão performa melhor.
A diferença entre um modelo que apenas responde e um sistema com ferramentas é a diferença entre um consultor que apenas opina e um assistente que realmente executa.
Mais do que isso: ferramentas transformam o modelo de um sistema de geração de texto em um sistema de ação no mundo. E essa mudança de paradigma — de resposta para ação — é uma das transformações mais fundamentais da nova infraestrutura de IA.
O nascimento dos agentes
Até aqui, descrevemos componentes: modelos, memória, contexto, ferramentas. Mas há uma pergunta fundamental ainda sem resposta: quem decide como e quando usar cada um desses componentes?
A resposta é o agente.
Em ciência da computação, um agente é um sistema que percebe seu ambiente e age sobre ele para alcançar objetivos. Em sistemas de IA modernos, um agente é um modelo de linguagem equipado com memória, contexto, ferramentas e, crucialmente, a capacidade de planejar, executar, observar e corrigir.
Esse ciclo — conhecido como Agent Loop ou ciclo Think-Act-Observe — é o que diferencia estruturalmente um agente de um chatbot:
- Planejar (Think): o agente recebe um objetivo e elabora um plano de ação, decidindo quais passos são necessários para alcançá-lo.
- Executar (Act): o agente executa o próximo passo do plano, o que pode incluir chamar ferramentas, consultar memória ou gerar conteúdo.
- Observar (Observe): o agente recebe o resultado da ação — o retorno da ferramenta, o dado recuperado, o erro encontrado.
- Corrigir (Reflect): com base na observação, o agente ajusta o plano e decide o próximo passo.
Esse padrão foi formalizado no artigo ReAct: Synergizing Reasoning and Acting in Language Models, de Yao et al. (2022), publicado no ICLR 2023. Os autores demonstraram que combinar raciocínio (reasoning) com ação (acting) em um loop iterativo melhora significativamente a capacidade dos modelos de resolver tarefas complexas — especialmente aquelas que exigem múltiplos passos, consulta a fontes externas e correção de erros intermediários.
A diferença entre chatbot e agente pode ser descrita assim:
Chatbot: pergunta → resposta.
Agente: objetivo → plano → ação → observação → ajuste → nova ação → resultado.
Um chatbot responde à pergunta “Quais são os principais concorrentes da empresa X?” com uma lista.
Um agente recebe o objetivo “Faça uma análise competitiva completa da empresa X” e, de forma autônoma, pesquisa fontes públicas, extrai dados financeiros disponíveis, organiza as informações em categorias comparativas, gera um relatório estruturado e — se instruído — o formata e encaminha por e-mail para os stakeholders relevantes.
A diferença não é apenas de qualidade. É de natureza.
Segundo o guia Building Effective Agents, publicado pela Anthropic em dezembro de 2024 e escrito por Erik Schluntz e Barry Zhang, a chave para agentes eficazes não é a complexidade do framework, mas a clareza das instruções, a qualidade das ferramentas disponíveis e a capacidade do sistema de reconhecer e recuperar erros. A Anthropic recomenda “começar com a solução mais simples possível e aumentar a complexidade apenas quando necessário” — um princípio que soa trivial, mas que representa uma mudança importante em relação à tendência de criar sistemas excessivamente elaborados.
MCP: o USB da Inteligência Artificial
À medida que agentes se tornaram mais sofisticados, um problema prático começou a se tornar crítico: como conectar modelos de linguagem a ferramentas e sistemas externos de forma padronizada e escalável?
Antes de 2024, a resposta era: cada empresa fazia do seu jeito. Para integrar um modelo de IA a um banco de dados, a um serviço de e-mail, a um sistema de CRM ou a qualquer outra ferramenta, os desenvolvedores precisavam escrever integrações customizadas para cada combinação de modelo e serviço. Era o equivalente a precisar de um cabo diferente para cada dispositivo eletrônico.
Os engenheiros chamavam esse problema de “M × N problem”: M modelos de IA conectados a N ferramentas externas resultam em até M × N integrações distintas para construir e manter. Inescalável.
Em 25 de novembro de 2024, a Anthropic anunciou o Model Context Protocol (MCP) — uma especificação aberta para padronizar como modelos de linguagem se comunicam com ferramentas, dados e serviços externos. O protocolo foi criado pelos engenheiros David Soria Parra e Justin Spahr-Summers.
A analogia que a própria Anthropic usa é precisa: MCP é para a IA o que o USB foi para os computadores.
Antes do USB, cada dispositivo — impressora, mouse, teclado, câmera — tinha seu próprio conector proprietário. Você precisava de adaptadores específicos e os fabricantes desenvolviam drivers para cada combinação de dispositivo e sistema operacional.
O USB criou um padrão universal: um conector, um protocolo, um sistema de plug-and-play. Qualquer dispositivo USB funciona em qualquer computador USB. O ecossistema explodiu.
O MCP aplica a mesma lógica: qualquer ferramenta construída segundo a especificação MCP funciona com qualquer modelo compatível com MCP. M + N integrações em vez de M × N.
Tecnicamente, o MCP define três tipos de primitivos que um servidor pode expor:
- Tools (Ferramentas): ações executáveis pelo modelo — buscar dados, criar arquivos, enviar mensagens.
- Resources (Recursos): dados acessíveis pelo modelo — documentos, registros de banco de dados, arquivos.
- Prompts (Templates): instruções reutilizáveis pré-configuradas para casos de uso comuns.
A adoção foi extraordinariamente rápida. Em menos de seis meses do lançamento, o MCP havia sido adotado como padrão de facto por praticamente todo o setor: OpenAI (ChatGPT), Google, Microsoft Copilot, Cursor, VS Code e dezenas de outros produtos e plataformas anunciaram suporte nativo. Em dezembro de 2025, a Anthropic doou o MCP à Agentic AI Foundation, vinculada à Linux Foundation, estabelecendo governança neutra e multi-empresa para o protocolo. Em maio de 2026, o registro oficial contabilizava quase 10.000 servidores MCP ativos — conectando modelos a GitHub, Google Drive, Slack, Notion, bancos de dados SQL, sistemas de arquivos, navegadores e centenas de outros serviços.
A importância estratégica do MCP vai além da conveniência técnica. Ao criar um protocolo padrão e aberto, ele está pavimentando a fundação para um ecossistema de ferramentas de IA interoperáveis: um mercado onde desenvolvedores criam conectores uma vez e eles funcionam para múltiplos modelos e sistemas. É a infraestrutura de conectividade da nova camada de IA.
Protocolos: a linguagem invisível da nova internet
A história da internet é, em grande parte, a história dos seus protocolos.
TCP/IP permitiu que computadores diferentes se comunicassem. HTTP permitiu que documentos fossem transferidos pela rede. SMTP viabilizou o e-mail. HTTPS adicionou criptografia. Cada protocolo resolveu um problema de comunicação e, ao fazê-lo, abriu um novo conjunto de possibilidades para aplicações construídas sobre ele.
A IA moderna está criando uma nova camada de protocolos.
O MCP é o exemplo mais visível, mas ele é parte de um movimento maior. Assim como o MCP resolve a comunicação entre modelos e ferramentas, uma segunda questão se tornava urgente: como diferentes agentes se comunicam entre si?
Em 9 de abril de 2025, durante o Google Cloud Next, o Google anunciou o Agent2Agent Protocol (A2A) — uma especificação aberta para comunicação direta entre agentes de diferentes fornecedores e frameworks. Diferente do MCP, que conecta agentes a ferramentas, o A2A conecta agentes a outros agentes — permitindo que um sistema delegue subtarefas a agentes especializados sem que nenhum deles precise expor sua lógica interna, sua memória ou seus detalhes de implementação.
O lançamento aconteceu com mais de 50 parceiros fundadores — incluindo Atlassian, Box, LangChain, MongoDB, PayPal, Salesforce, SAP, ServiceNow e Workday — e contou com o suporte de grandes consultorias como Accenture, Deloitte, McKinsey e PwC. Em junho de 2025, o Google doou o A2A à Linux Foundation, estabelecendo governança neutra. Em 2026, o protocolo já contava com mais de 150 organizações participantes.
Dois protocolos, dois problemas diferentes:
- MCP: como agentes se conectam a ferramentas e dados.
- A2A: como agentes se comunicam com outros agentes.
Juntos, eles estão definindo o que pode se tornar a pilha de protocolos da internet dos agentes — da mesma forma que TCP/IP + HTTP definiram a pilha da internet dos documentos.
Assim como a popularização do HTTP não exigiu que os usuários entendessem como os pacotes TCP são roteados, o uso cotidiano de agentes de IA não exigirá que as pessoas entendam MCP ou A2A. Mas esses protocolos determinarão o que é possível construir, com quanta interoperabilidade e a que custo.
Protocolos não são glamourosos. São invisíveis. E exatamente por isso são tão poderosos.
Orquestração: quem coordena tudo isso?
Imagine uma grande consultoria com centenas de especialistas: analistas financeiros, advogados, engenheiros, pesquisadores de mercado, designers. Para resolver um problema complexo de um cliente, você precisa coordenar o trabalho dessas pessoas — definir quem faz o quê, em que ordem, como as informações circulam entre eles, quem revisa o trabalho de quem e como tudo se consolida em uma entrega final coerente.
Isso é orquestração.
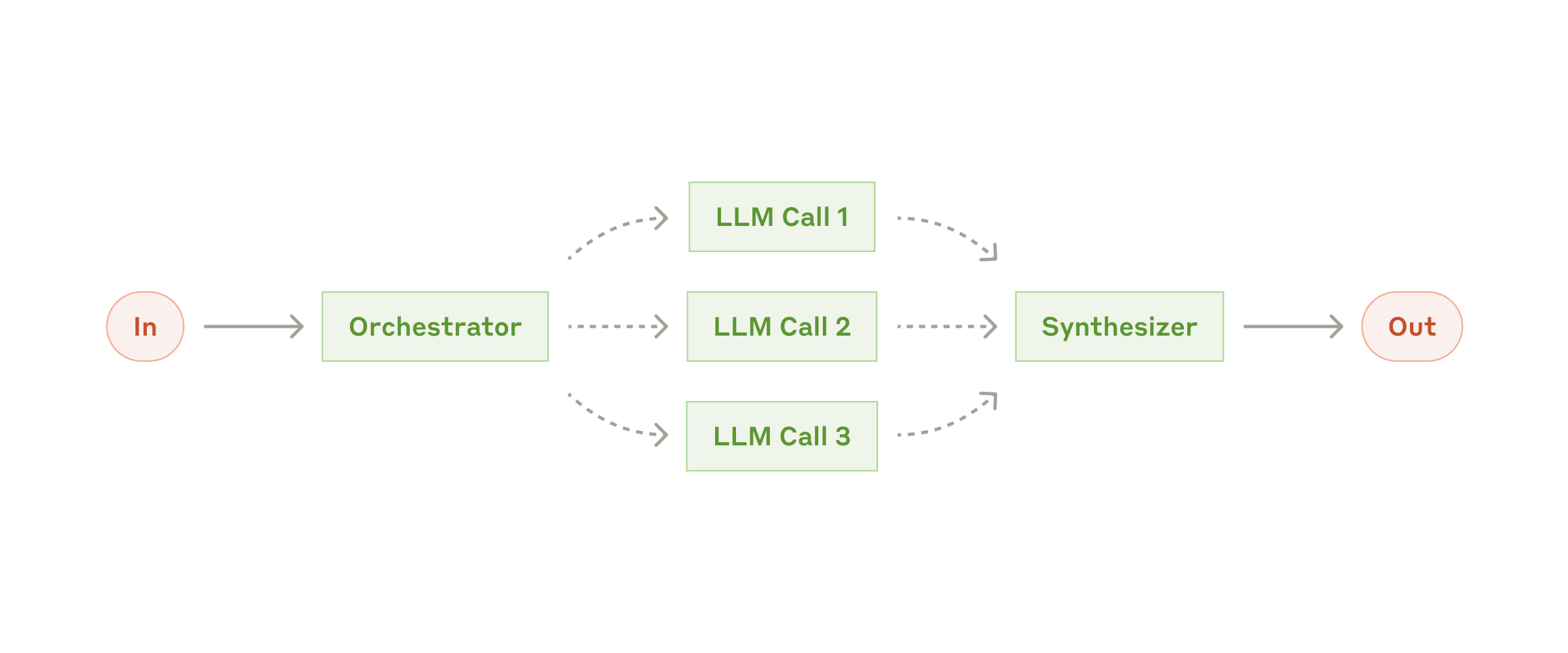
Em sistemas de IA modernos, orquestração é o problema de coordenar múltiplos modelos, agentes, ferramentas e fluxos de trabalho para executar tarefas complexas. É o que determina como o sistema como um todo se comporta, mesmo que cada componente individual seja relativamente simples.
Existem três arquiteturas principais:
Single-Agent: um único agente com acesso a múltiplas ferramentas. Simples, eficiente para tarefas focadas, mas limitado pela janela de contexto e pela dificuldade de gerenciar muitas dimensões simultaneamente.
Multi-Agent: múltiplos agentes especializados, coordenados por um agente orquestrador. O orquestrador divide tarefas complexas em subtarefas, delega para agentes especializados, coleta resultados e os integra. Mais robusto e escalável, mas com maior complexidade de gerenciamento e depuração.
Agent Swarms: sistemas com muitos agentes que colaboram sem um orquestrador centralizado, através de mecanismos de coordenação emergente. Ainda em estágio predominantemente de pesquisa para casos de uso práticos, mas com aplicações promissoras em tarefas de exploração, geração criativa em larga escala e problemas de busca complexa.
Frameworks como LangChain, LlamaIndex, CrewAI, AutoGen da Microsoft e o Agents SDK da OpenAI surgiram para resolver o problema de orquestração em nível de produto. Cada um oferece abstrações diferentes para construir, conectar e gerenciar agentes e fluxos de trabalho.
A Anthropic, em seu guia Building Effective Agents (dezembro de 2024), argumenta que a maioria dos problemas práticos pode ser resolvida com padrões relativamente simples de orquestração — como prompt chaining, routing, parallelization e orchestrator-workers — e que a complexidade deve ser adicionada apenas quando necessária. “A maioria das implementações bem-sucedidas que vimos”, escreveram Schluntz e Zhang, “não usava frameworks complexos nem bibliotecas especializadas. Elas construíam com padrões simples e combináveis.”
O princípio é análogo ao bom design de software: simplicidade primeiro, complexidade somente quando justificada pelos requisitos reais.
O que está emergindo, no entanto, é a possibilidade concreta de sistemas onde múltiplos agentes especializados colaboram de forma autônoma para resolver problemas que nenhum agente individual conseguiria resolver sozinho. Sistemas que se assemelham menos a um software tradicional e mais a uma organização digital.
Estamos criando uma nova camada da internet?
A pergunta que intitula esta seção não é retórica. É uma pergunta técnica com evidências crescentes a favor de uma resposta afirmativa.
Para respondê-la com rigor, é útil olhar para como a internet evoluiu historicamente:
A internet dos documentos (1990s): navegadores, HTML, HTTP. A internet era uma coleção de documentos estáticos. Você acessa páginas, lê conteúdo. A inteligência estava no humano; a internet era passiva.
A internet das aplicações (2000s–2010s): JavaScript, APIs, computação em nuvem, aplicativos móveis. A internet começou a executar lógica. Serviços como Google, Amazon, Facebook e Uber não eram apenas documentos — eram aplicações que processavam dados, tomavam decisões e executavam ações em tempo real.
A internet dos agentes (2020s–): sistemas de IA com memória, contexto, ferramentas e capacidade de agir de forma autônoma. A internet começa a ter intenção. Não apenas executa lógica definida explicitamente por humanos, mas interpreta objetivos, planeja, age e se adapta.
Os sinais dessa transição já são amplamente visíveis:
Agentes pessoais: assistentes que conhecem as preferências do usuário, gerenciam agenda, organizam comunicações, monitoram interesses e executam tarefas cotidianas de forma autônoma.
Agentes corporativos: sistemas que monitoram pipelines de vendas, disparam alertas, geram relatórios, respondem clientes, qualificam leads e integram dados de múltiplos sistemas sem intervenção humana.
Agentes de pesquisa e análise: sistemas que varrem literatura científica, identificam padrões, formulam hipóteses e apontam lacunas de conhecimento em velocidades impossíveis para pesquisadores individuais.
Agentes de desenvolvimento de software: ferramentas como GitHub Copilot Workspace e Claude Code que recebem requisitos e produzem código, testam, depuram e iteração de forma semi-autônoma.
Agentes colaborativos: redes de agentes especializados que colaboram para resolver problemas complexos — combinando análise jurídica, financeira, técnica e estratégica em um único fluxo de trabalho integrado.
O que está emergindo não é simplesmente uma nova categoria de software. É uma nova camada de abstração sobre a infraestrutura digital existente — uma camada que converte intenção em ação, que conecta modelos a dados e ferramentas, que coordena processos complexos por meio de múltiplos sistemas.
Assim como a computação em nuvem não substituiu a internet, mas criou uma nova infraestrutura sobre ela, a IA agentiva não está substituindo a internet das aplicações — está criando uma nova camada acima dela.
Uma camada onde o ator principal não é o usuário digitando comandos, mas o agente interpretando intenções e executando sequências de ações para realizá-las. Uma camada que tem seus próprios protocolos (MCP, A2A), seus próprios padrões arquiteturais (single-agent, multi-agent, swarms), sua própria infraestrutura de memória e contexto.
E, como todas as camadas anteriores da internet, ela está sendo construída de forma incremental, distribuída, por milhares de pesquisadores, engenheiros e organizações ao redor do mundo.
O que muda para empresas e profissionais
Uma nova camada computacional não é um fenômeno puramente técnico. Ela reorganiza como o trabalho é feito, quais habilidades têm valor, como as empresas competem e o que é possível criar.
A computação em nuvem não apenas criou novos tipos de infraestrutura — ela democratizou o acesso à capacidade computacional, possibilitou o surgimento de startups que não precisavam mais de servidores físicos e transformou a TI corporativa. A camada de IA agentiva promete uma transformação de escala similar, mas de natureza diferente: não democratiza apenas a infraestrutura, mas a capacidade de execução.
O impacto já é visível nas principais áreas do trabalho do conhecimento:
Trabalho analítico e intelectual: tarefas que antes exigiam horas de pesquisa, síntese e formatação — relatórios, análises, propostas comerciais, estudos de mercado — podem ser delegadas a agentes que executam o processo de ponta a ponta, deixando o profissional humano para revisar, decidir e contextualizar. O gargalo deixa de ser a execução e passa a ser o julgamento.
Engenharia de software: o ciclo de desenvolvimento está se transformando. Agentes de código assistem na geração, testam automaticamente, identificam bugs, sugerem refatorações e documentam. Não eliminam engenheiros — mas ampliam dramaticamente a produtividade e deslocam o valor das habilidades de execução para as de arquitetura, revisão crítica e definição de requisitos.
Atendimento ao cliente: sistemas agentivos modernos vão além de responder perguntas frequentes. Eles consultam sistemas internos em tempo real, personalizam respostas com base no histórico do cliente, escalam para humanos nos casos corretos e aprendem com cada interação — criando um ciclo de melhoria contínua.
Marketing e comunicação: agentes de conteúdo monitoram tendências, identificam oportunidades, geram variações para testes, personalizam mensagens por segmento e medem resultados — comprimindo ciclos que antes levavam semanas para dias ou horas.
Pesquisa e educação: agentes de pesquisa varrem fontes, sintetizam literatura, identificam contradições e formulam perguntas de acompanhamento. Tutores adaptativos personalizam currículos em tempo real com base no desempenho e nas dificuldades específicas do estudante.
Finanças e compliance: sistemas de monitoramento agentivo rastreiam portfólios, identificam anomalias, geram alertas, compilam relatórios regulatórios e executam reconciliações que antes demandavam equipes inteiras.
Saúde: agentes de análise combinam literatura médica, histórico do paciente e protocolos institucionais para apoiar diagnósticos e planos de tratamento — não como substitutos de médicos, mas como amplificadores da capacidade clínica.
A transformação mais importante, porém, é sistêmica: a unidade básica de trabalho está mudando.
Em muitas áreas, a tarefa não será mais “escrever um relatório” mas “definir o objetivo do relatório, revisar o output do agente e tomar decisões sobre ele”. A habilidade humana central não será a execução, mas a direção, o julgamento e a curadoria.
Isso não é uma promessa otimista sem fundamento. É uma inferência direta das capacidades que já existem em sistemas de IA operacionais em 2025–2026. O que permanece em aberto é a velocidade e a escala da adoção — não a direção da mudança.
Conclusão
A maioria das pessoas acredita que a revolução da IA é o chatbot.
Isso é compreensível. O chatbot é visível, acessível e imediato. Você abre o navegador, digita uma pergunta, recebe uma resposta extraordinária de um sistema que, há cinco anos, seria considerado ficção científica. É uma mudança genuína e impressionante.
Mas os chatbots — assim como os primeiros navegadores da web nos anos 1990 — provavelmente serão lembrados como a primeira interface visível de algo muito maior.
Por trás deles está surgindo uma infraestrutura que combina:
- Modelos de linguagem capazes de raciocínio e geração sofisticados
- Sistemas de memória persistente que permitem aprendizado ao longo do tempo
- Mecanismos avançados de gerenciamento de contexto e recuperação de informação
- Capacidades de uso de ferramentas que transformam resposta em ação
- Protocolos abertos — como o MCP e o A2A — que padronizam a comunicação entre componentes
- Agentes com capacidade de planejamento e execução autônoma de tarefas complexas
- Frameworks de orquestração que coordenam múltiplos agentes e fluxos de trabalho
Cada uma dessas peças já existe. Cada uma está em uso em sistemas reais e em produção. O que ainda está se consolidando é a forma como elas se articulam em uma infraestrutura coerente, padronizada e universal.
A analogia histórica mais precisa não é a invenção do computador pessoal, nem o surgimento da internet. É a criação do TCP/IP: um conjunto de protocolos invisíveis que definiram como tudo se comunicaria, e sobre os quais foram construídas décadas de inovação que ninguém, em 1974, conseguia prever em detalhes.
O TCP/IP da IA ainda está sendo escrito. Mas seus contornos estão ficando mais nítidos.
Talvez estejamos assistindo, agora, ao nascimento de um novo sistema operacional para a internet. Um sistema que não roda em nenhum computador específico, mas que se distribui por toda a infraestrutura digital existente. Que não tem uma interface única, mas que está presente em todos os sistemas que tocamos. Que não foi projetado por uma única empresa, mas que está emergindo da colaboração — e da competição — de pesquisadores, engenheiros e organizações ao redor do mundo.
Um sistema operacional invisível.
Que já está rodando.
Referências
ANTHROPIC. Building Effective Agents. Anthropic Engineering Blog, 19 dez. 2024. Disponível em: https://www.anthropic.com/engineering/building-effective-agents. Acesso em: jun. 2026.
ANTHROPIC. Introducing the Model Context Protocol. Anthropic News, 25 nov. 2024. Disponível em: https://www.anthropic.com/news/model-context-protocol. Acesso em: jun. 2026.
ANTHROPIC. Model Context Protocol — Introduction. Model Context Protocol Documentation, 2024. Disponível em: https://modelcontextprotocol.io/introduction. Acesso em: jun. 2026.
ANTHROPIC. Tool Use Documentation. Anthropic Claude Docs, 2024. Disponível em: https://docs.anthropic.com/en/docs/build-with-claude/tool-use. Acesso em: jun. 2026.
GOOGLE. Announcing the Agent2Agent Protocol (A2A). Google Developers Blog, 9 abr. 2025. Disponível em: https://developers.googleblog.com/en/a2a-a-new-era-of-agent-interoperability/. Acesso em: jun. 2026.
LANGCHAIN. Memory — Conceptual Guide. LangChain Documentation, 2024. Disponível em: https://python.langchain.com/docs/concepts/memory/. Acesso em: jun. 2026.
LEWIS, Patrick et al. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. In: ADVANCES IN NEURAL INFORMATION PROCESSING SYSTEMS, 33., 2020, Vancouver. Anais… [S.l.]: NeurIPS, 2020. Disponível em: https://arxiv.org/abs/2005.11401. Acesso em: jun. 2026.
MICROSOFT RESEARCH. AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation. Microsoft AutoGen, 2024. Disponível em: https://microsoft.github.io/autogen/. Acesso em: jun. 2026.
OPENAI. Function Calling — Guide. OpenAI Platform Documentation, 2023. Disponível em: https://platform.openai.com/docs/guides/function-calling. Acesso em: jun. 2026.
SCHLUNTZ, Erik; ZHANG, Barry. Building Effective Agents. Anthropic, 19 dez. 2024. Disponível em: https://www.anthropic.com/engineering/building-effective-agents. Acesso em: jun. 2026.
VASWANI, Ashish et al. Attention Is All You Need. In: ADVANCES IN NEURAL INFORMATION PROCESSING SYSTEMS, 30., 2017, Long Beach. Anais… [S.l.]: NeurIPS, 2017. Disponível em: https://arxiv.org/abs/1706.03762. Acesso em: jun. 2026.
WANG, Lei et al. A Survey on Large Language Model based Autonomous Agents. arXiv, ago. 2023. Disponível em: https://arxiv.org/abs/2308.11432. Acesso em: jun. 2026.
YAO, Shunyu et al. ReAct: Synergizing Reasoning and Acting in Language Models. In: INTERNATIONAL CONFERENCE ON LEARNING REPRESENTATIONS, 11., 2023, Kigali. Anais… [S.l.]: ICLR, 2023. Disponível em: https://arxiv.org/abs/2210.03629. Acesso em: jun. 2026.